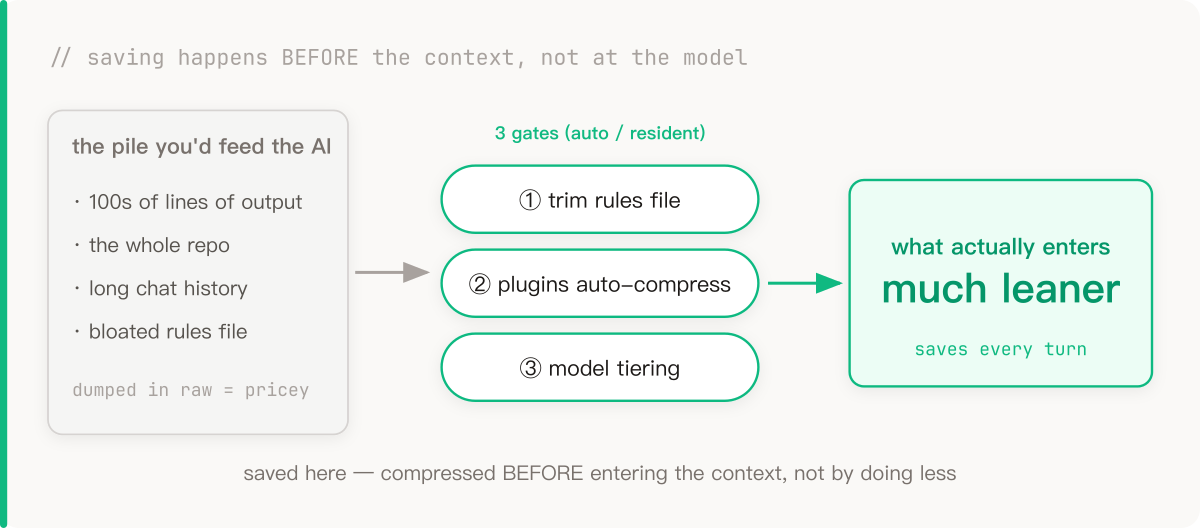
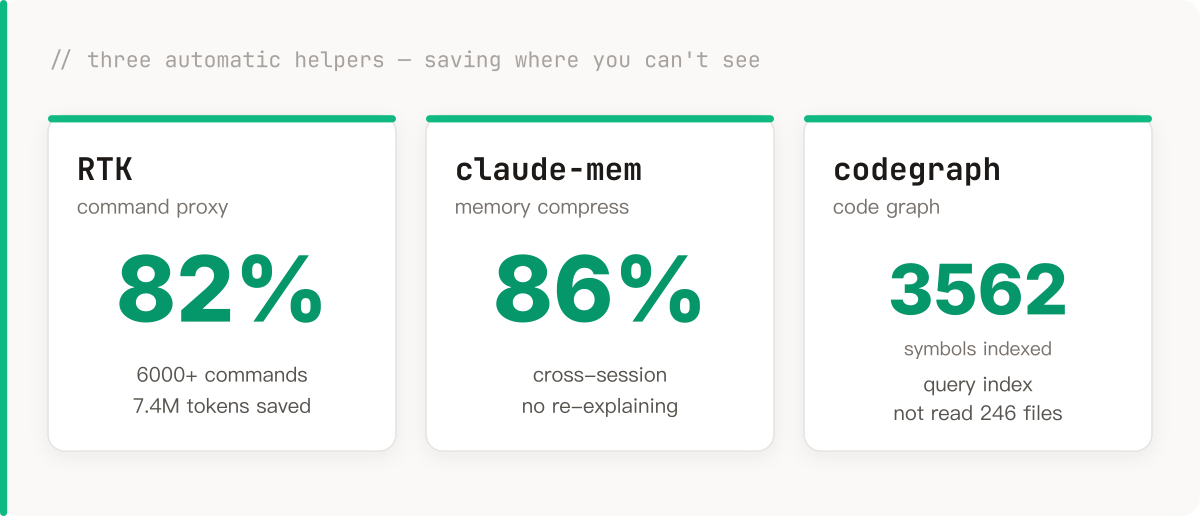
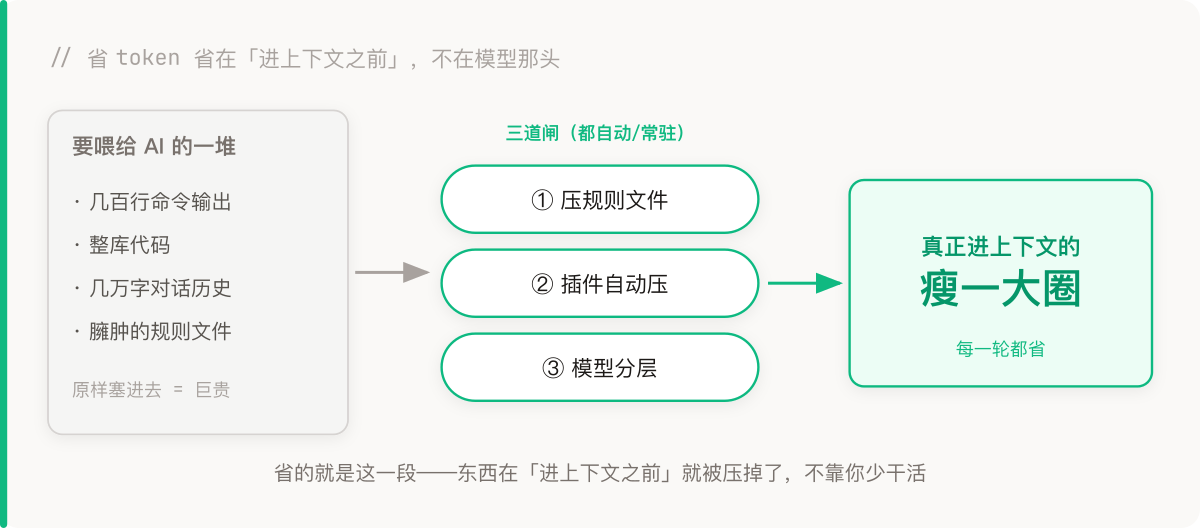
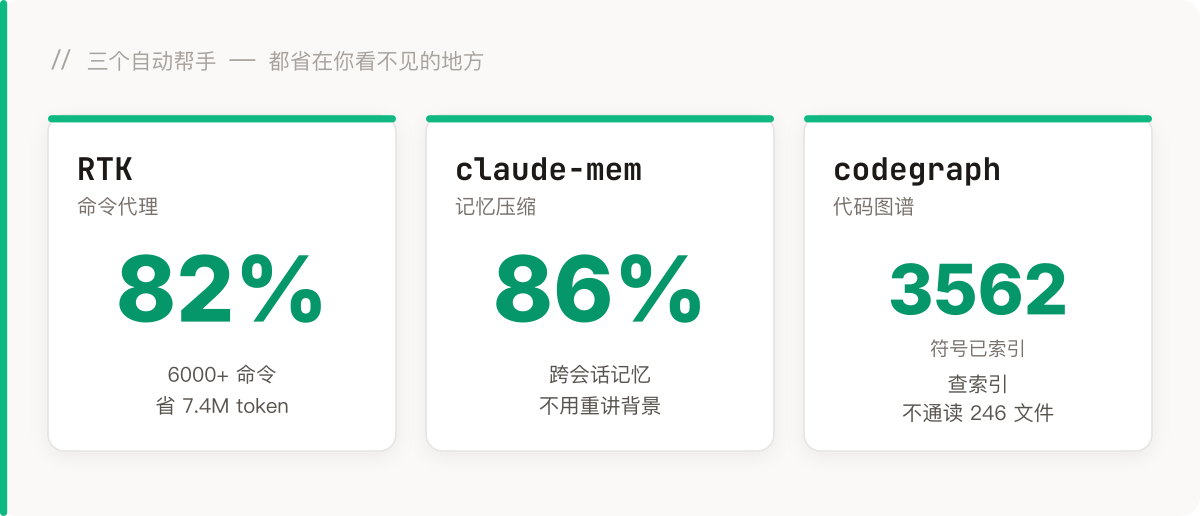
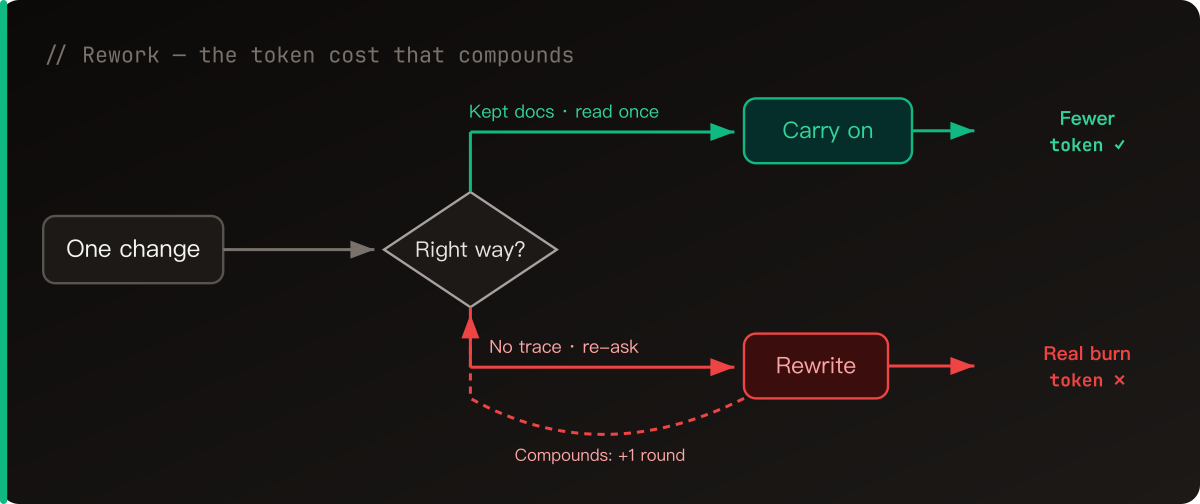
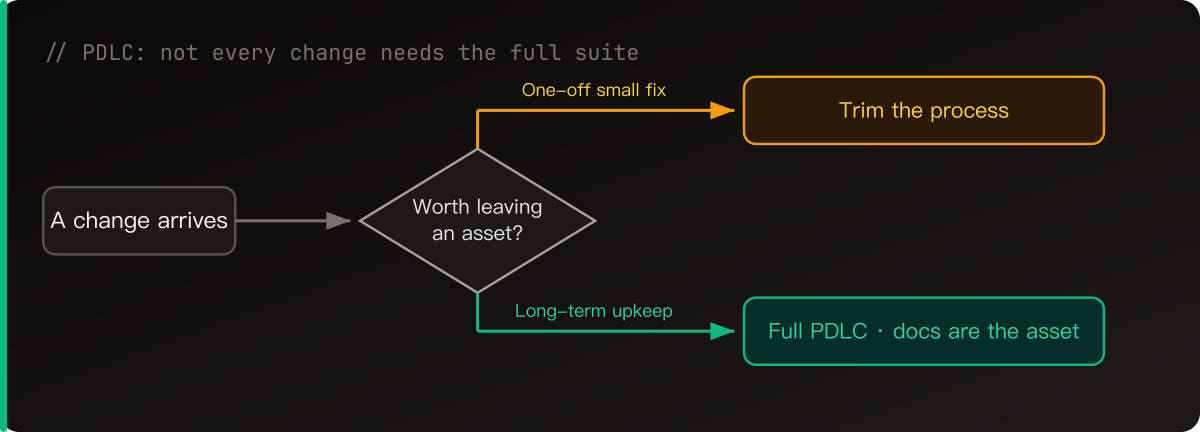
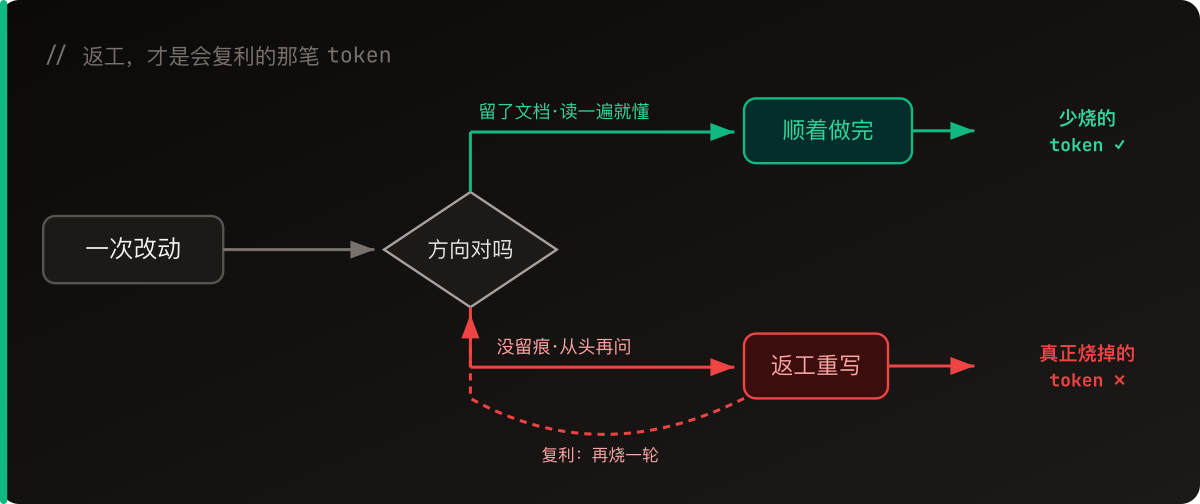
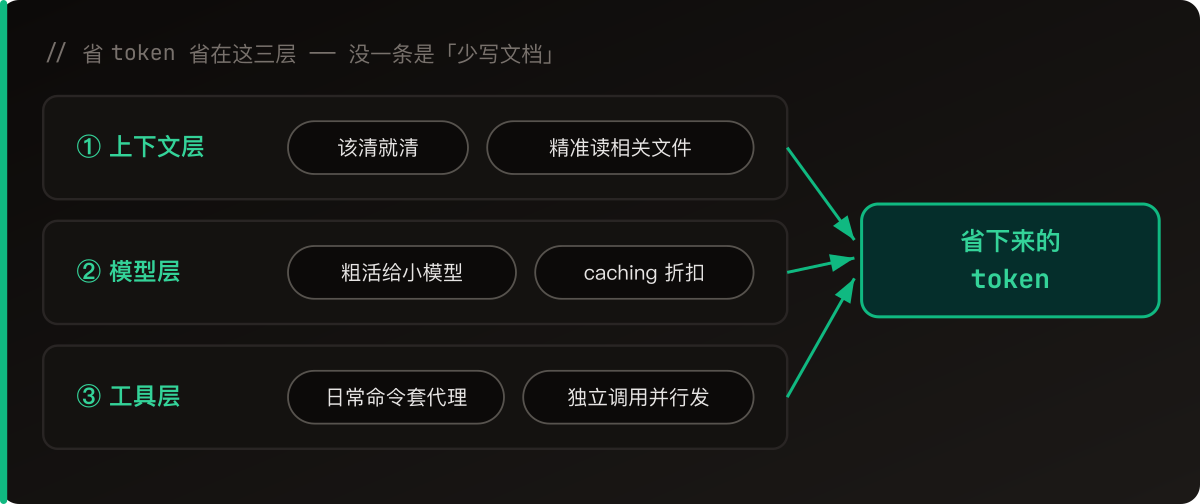
Then it clicked: a lot of these modules have nothing to do with each other, so why make them go one after another? Split them up, let several agents work at the same time, done.
What I want, and where it stops
What I want is simple: the same work, for roughly the same tokens, with the wall-clock time cut way down.
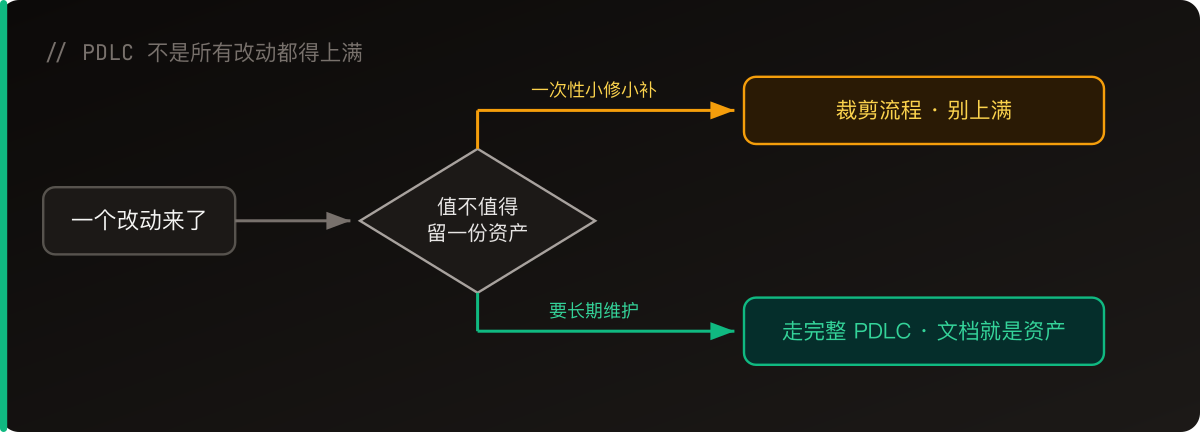
But let me put the boundary up front—not every task can be split this way. This is just an approach I’ve worked out for myself; take what’s useful.
The prerequisite: a clean architecture
For several agents to work at once without stepping on each other, the prerequisite isn’t the AI—it’s your architecture.
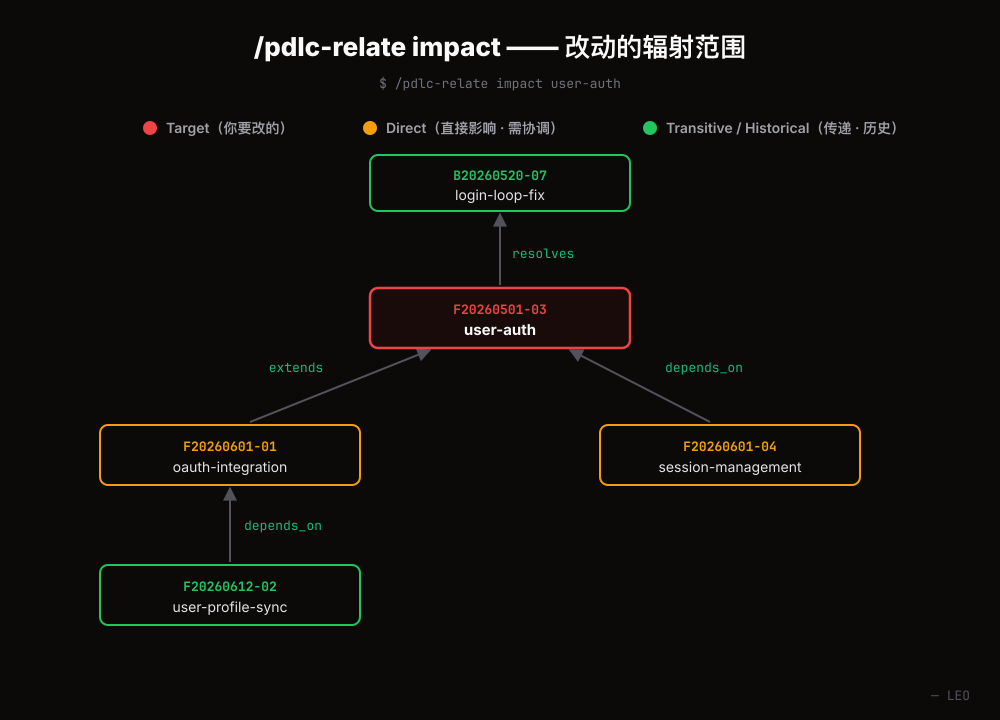
That task of mine could be split because it was already several modules, talking to each other through interfaces, with internal implementations that don’t affect one another—as long as each one honors the interface contract, it can be built independently. Loosely coupled, highly cohesive, in other words. And I’d nailed that design down together with opus before writing a line: opus helps me think it through and lays out options, but I’m the one who decides.
You can’t cut corners here. Forcing parallelism onto an architecture you haven’t cleanly split is like cutting a tangle of yarn into a few pieces that are all still knotted together—it only gets messier.
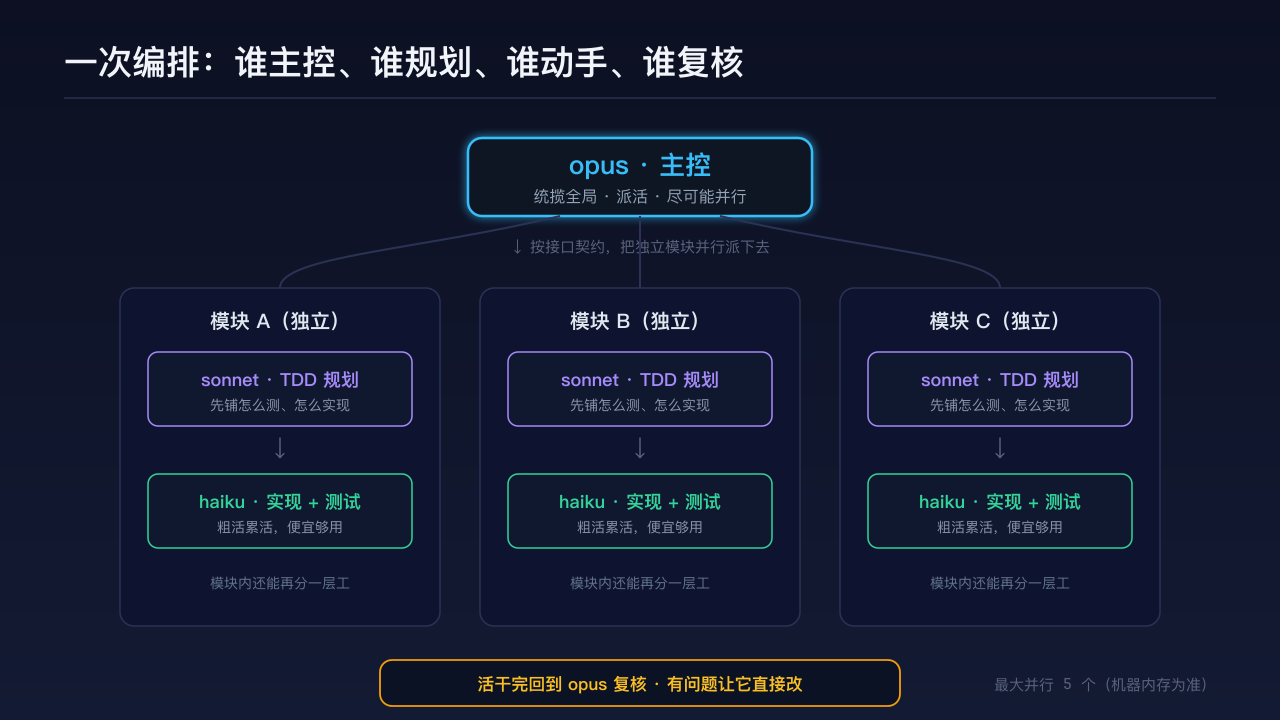
Who runs the show, who plans, who does the work
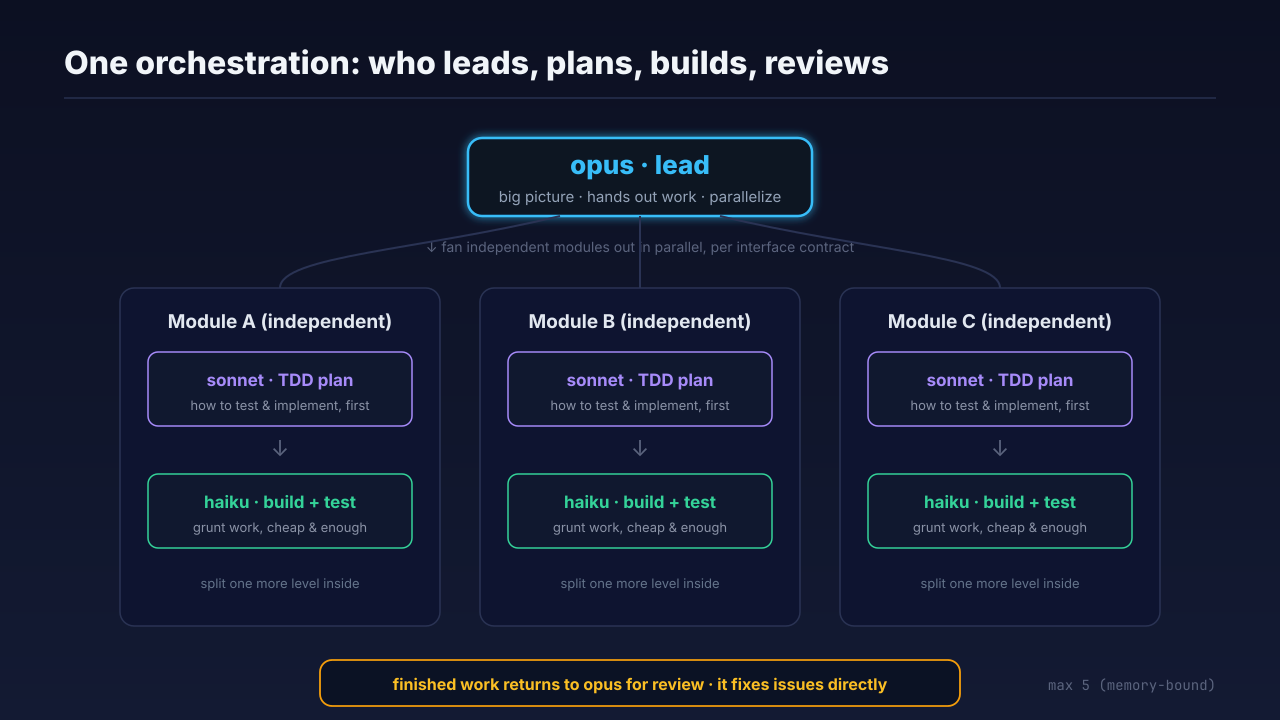
With the design settled, it’s time to assign roles. The split I tend to use:
- opus runs the show—holds the big picture, hands out work, does the final check;
- sonnet does the TDD planning—per the design, it lays out how each module gets tested and implemented;
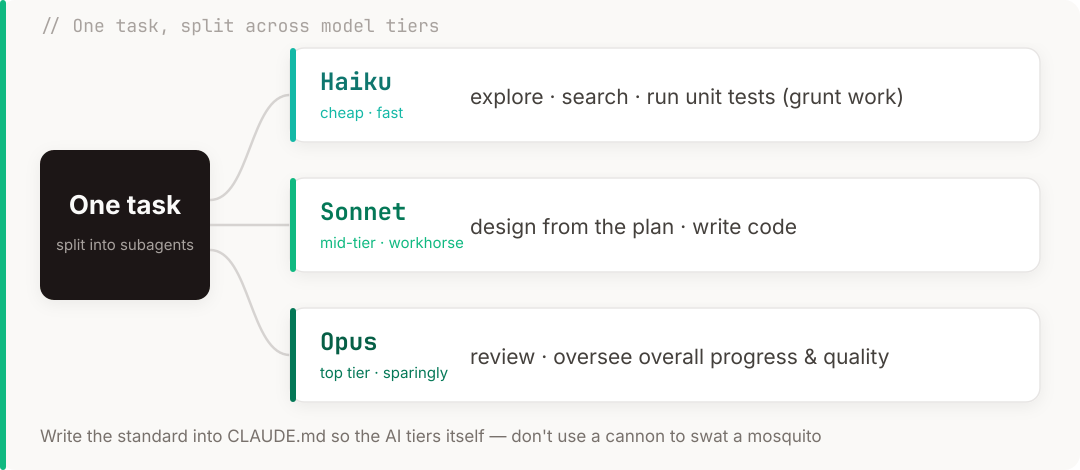
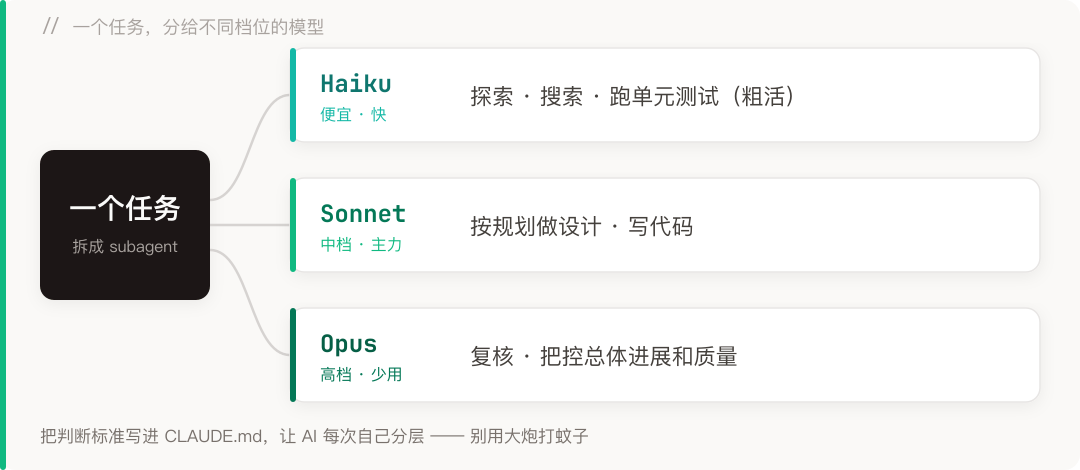
- haiku writes the code and runs the tests—the grunt work goes to it, cheap and good enough.
This split is really a continuation of last post’s “model tiering”—use the good steel on the blade. Except last time the point was saving money; this time it’s about how these roles work together.
How you fan them out
In practice, I did three things:
- Wrote one line into the global CLAUDE.md: “Parallelize when you can.” That’s the default rule across all projects.
- Set the max number of concurrent subagents in Claude’s settings—that’s the valve that actually matters.
- Added one reminder every time I give an instruction: “Parallelize as much as possible.” opus, as the lead, already fans work out on its own, but a nudge keeps it on track.
The lead hands modules down, and inside a module it can split the work one more level. Layer over layer, and the whole task spreads out.
The review step you don’t skip
Running fast in parallel—how do you keep quality up? My answer: let the lead review its own output.
The logic is direct: it handed out the work, so it knows exactly what each subagent owes. Having it do the checking is the natural fit. I tried setting up a separate dedicated review agent, and it just had to re-understand the whole task from scratch—burning another round of tokens and being slower for it. The lead reviewing itself saves that re-understanding overhead, and it’s both faster and sharper.
There’s a small detail after a problem turns up: the lead usually asks me, “Should I fix this directly, or spin up another agent to do it?” I almost always say “you fix it.” Because it’s the one that just caught the flaw—it knows best where the problem is, and the change is most direct coming from it.
The two pits I fell into
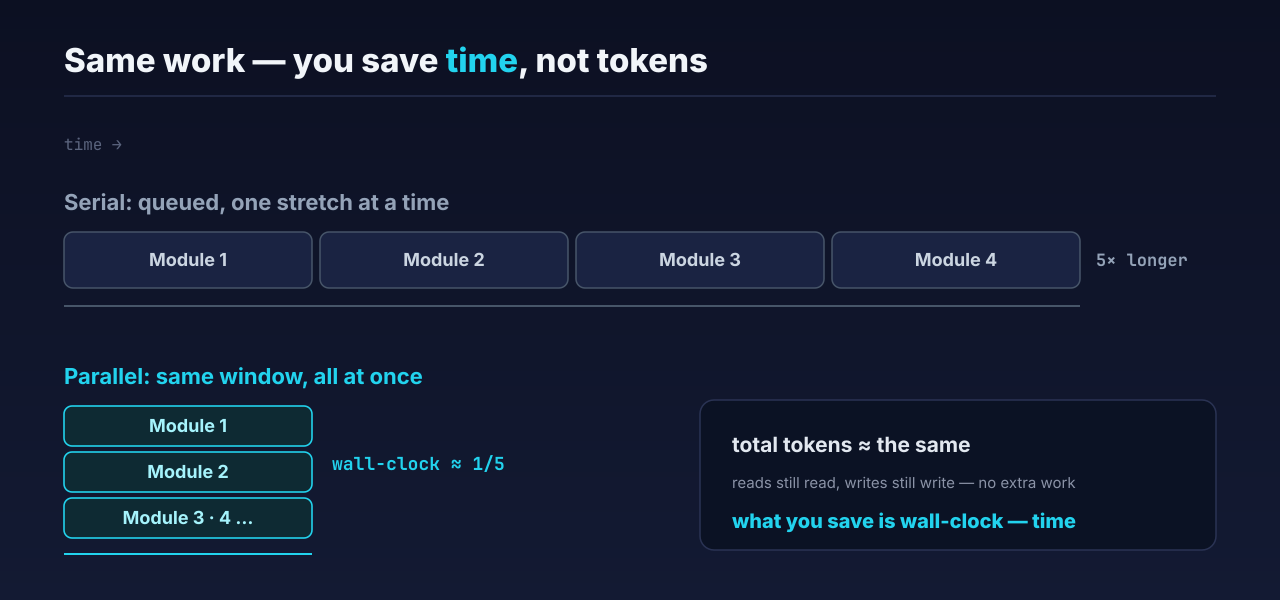
The first was memory. Early on I got greedy and set max concurrency to 10. But I had other projects running in parallel at the time, and the machine’s memory got eaten clean. So I honestly dropped it to 5, and it was actually better—for this one task alone, 5 in parallel is roughly 5× a serial run; stack on the other tasks running at the same time and the overall speedup tops 10×. If your machine and your quota can take it, push the number higher; if not, don’t force it.
The second: don’t split for the sake of splitting. Some modules are tightly coupled and meant to go in order, and if you pry them apart to parallelize, the agents interfere with each other and quality goes out the window. So before handing it off, I add a specific reminder: “These modules are coupled—don’t force a split.” Good news is plenty of AIs recognize this themselves and won’t force it. When something genuinely can’t be split, just hand it to one agent to do serially, or have the lead run that thread end to end.
A counterintuitive bit of math
Plenty of people hear “5 agents burning at once” and their first reaction is: won’t the tokens multiply?
The way I figure it, no. The same pile of work, done serially, burns roughly the same token count—what needs reading still gets read, what needs writing still gets written; parallelism doesn’t conjure up extra work. What parallelism actually changes isn’t the cost, it’s the wall-clock: the stretches that used to run in a queue now run in the same window together. The tiny bit of extra tokens buys a big drop in time cost—a great trade.
So apart from the things that genuinely can’t be split, these days I parallelize basically everything that can be.
Recap: three things to just do
One, clean architecture first, then talk parallelism. Loosely coupled, highly cohesive, talking through interface contracts—without that foundation, splitting is a disaster. Nail it down with the AI in the design phase.
Two, parallelize everything you can, but set a ceiling. Bigger isn’t better; size it against your machine’s memory and your AI quota. I went from 10 back to 5 because memory taught me a lesson.
Three, fast parallelism needs review. And the reviewer has to actually understand the task—have the lead that handed out the work do the checking, cheapest and sharpest; when it finds a problem, let it fix it directly.
One thing you can do today: open your global CLAUDE.md, add “parallelize when you can,” then go into settings and bump max concurrent subagents to a number your machine can handle. Next time you hand it a task that can be split, you’ll notice it stops queuing.
Next post I want to get into a problem that follows right on the heels of this one: when several agents edit code at the same time, what keeps them from clobbering each other? The answer is git worktree—giving each agent its own isolated workspace so they each work their own copy and nobody gets in anybody’s way. Let me know in the comments if you’re interested.
]]>