PDLC 1.1:v1.0 が成果物の形について犯した2つの間違い
目次
PDLC は Claude Code のプラグインです。33のステージ、成果物のディスクへの強制保存、per-feature の状態機械、テストファースト。v1.0 でその縦軸——feature の進行順序——を固めました。
v1.1 は横軸の修正です。ファイルの形と、feature 同士の関係。どちらも v1.0 では見えていなかった問題です。
RFC #5 — 成果物には2種類ある
v1.0 で /pdlc-arch を使い始めてすぐ、奇妙なことに気づきました。実行するたびに docs/architecture-2026-05-01.md、docs/architecture-2026-05-15.md……という日付付きファイルが増え続けます。3ヶ月後には30以上のファイルが散乱していました。
「今のシステムはどんな形?」という質問に答えようとすると、どのファイルが最新かを探すところから始まる。これは設計の間違いです。
根本原因は、2種類の成果物を同じ型として扱っていたことです。
ledger 型(台帳)は出来事を記録します。PRD、設計の決定——何をいつ考えたかの痕跡。これは上書きしてはいけない。時系列の蓄積がそのまま価値になります。
surface 型(現況面)は現在の状態を記録します。アーキテクチャ概要、チームの規約——「今どうなっているか」の答え。これは常に1つだけ存在し、更新されるべきです。
/pdlc-arch は docs/ARCHITECTURE.md を直接更新するように変更しました。遺留の日付付きファイルは docs/.archive/architecture/ へ自動で移動します。
新コマンド /pdlc-standard で docs/00_standards/ 以下の surface 型ドキュメントを管理します:
/pdlc-standard add "コードレビューポリシー"
/pdlc-standard edit "命名規約"
/pdlc-standard index
coding-style-v2.md のようなバージョン番号付きファイル名は、コマンド内でハードブロックしています。「就地で編集し、git log で履歴を追う」——これを強制することで、ファイルの増殖を根本から断ちます。
RFC #6 — feature は孤島ではない
v1.0 の feature ID は平坦です。F20260501-01——ただの連番で、feature 間の関係は誰も知りません。
実際には feature は必ず他の feature に依存するか、影響を与えます。その関係が暗黙知のままだと、変更の影響範囲が見えない。「この feature を変えたら何が壊れるか」の確認に、コードを全部読み返すことになります。
新コマンド /pdlc-relate は6種類の関係タイプを管理します:
| タイプ | 意味 |
|---|---|
extends |
この feature は別の feature の拡張 |
depends_on |
この feature は別の feature の実装を必要とする |
supersedes |
この feature が別の feature を置き換える |
resolves |
この feature が別の feature に起因する問題を修正する |
conflicts_with |
2つの feature に既知の競合がある |
relates_to |
上記に当てはまらない緩い関連 |
/pdlc-relate set F20260501-01 depends_on F20260415-03
/pdlc-relate query F20260501-01
最も使う場面はリファクタリングの前です:
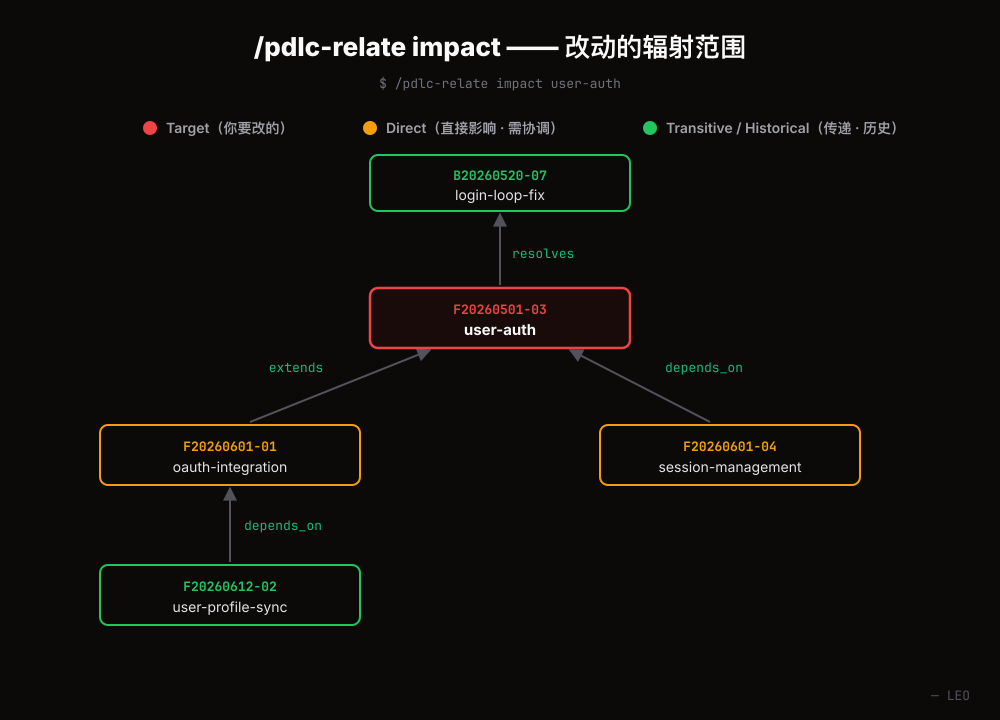
/pdlc-relate impact F20260501-01
3層で影響範囲を表示します。直接依存している feature(🔴 必ず協調)、間接依存(🟡 PRD を要確認)、過去に関係があった履歴(🟢 監査のみ)。変更前に確認することで、「動いていたものが壊れた」を大幅に減らせます。
実装して気づいた2つのこと
surface 型への移行は、思ったより手間がかかりました。既存プロジェクトの古い日付付きファイルをどれが「最新」かを自動判定するのは難しい。結局 /pdlc-arch が遺留ファイルを検出すると「この architecture-2026-02-19.md を ARCHITECTURE.md の初期値として使いますか?」と確認を求める設計にしました。自動移行の誤りを防ぐためです。
関係タイプは、最初は3種類でした。「依存」「拡張」「競合」の3つで始めましたが、実プロジェクトで試すと表現できないケースが続出しました。例えば「この feature はあの feature の積み残し問題を修正した」という関係。最終的に6種類が十分な境界でした。それ以上増やすと分類ゲームになります。
現在の状態
v1.1.0 はリリース済みです。自分のプロジェクト(aitm、pdlc-skills 自体)で3ヶ月ほど使っています。
ledger/surface の分離は docs/ ディレクトリを「タイムライン」から「情報を探せる場所」に変えました。/pdlc-relate impact はクロス feature の変更の前に毎回使っています。
v1.0 からの移行はほぼ無感覚です。/pdlc-arch の初回実行時に遺留ファイルの確認が入る以外、既存のワークフローは変わりません。
インストール / アップグレード
新規インストール(Claude Code が必要):
/claude install kanfu-panda/pdlc-skills
アップグレード:
bash <(curl -fsSL https://raw.githubusercontent.com/kanfu-panda/pdlc-skills/main/install.sh) --upgrade
ソースコードは GitHub にて MIT ライセンスで公開中です。
次回
PDLC は工程を細かく分け、各ステップで成果物を残します。利点はステップを飛ばさない・脱線しないこと。代償は、ただ AI に書かせるより token を多く食うこと。今日もある人に言われました——「ドキュメントが増えれば、token もその分かさむのでは?」
これは一本立てて書く価値があります。この token の勘定が実際どう積み上がるのか(正確には測っていませんが、直感に反する部分があります)、そしてこの重めのプロセスを回しながら、どうコストを抑えているか。token を節約するのは結局お金の節約ですが、お金だけの話でもありません。
コメント