トークンを食っているのはドキュメントではない、ツールの使い方だ
目次
PDLC でプロジェクトを進めていると、必ずこう聞かれます——ドキュメントだらけで、PRD も設計もレビューも一通りやって、トークンが燃え尽きるんじゃないか、と。
もっともな疑問です。プロセスを細かいステージに分け、各ステップで成果物を残す——確かに「AI にそのままコードを書かせる」より高くつくように見えます。でも、私に言わせれば、そのトークンの請求書をドキュメントのせいにはできません。
先に結論を置きます。第一に、ドキュメントが多いことと、トークンを大量に食うことは別の話。第二に、本当にトークンを節約したいなら、答えはツールを正しく使うことであって、ドキュメントを削ることではありません。
トークンを正確に計測したわけではありません——同じプロジェクトを「ドキュメントあり vs なし」で2回走らせて、きれいなパーセンテージを出したわけでもない。語るのは体感と方法です。
トークンを食う原因は PDLC ではない
請求書を精算する前に、正しい債務者を見つけること。
トークンを食うのは、多くの場合 PDLC のせいではなく、ツールの使い方が間違っているからです。その「間違い」は具体的で、三つあります:
- コンテキスト:消すべきときに消さない。一つの会話を朝から晩まで開きっぱなしで、数万字の履歴が毎ターン再計算される。新しい質問をしているのに、古い借金を払っている。
- プロンプト:曖昧に書く。AI があなたの意図を何度も推測し、一度で済む話が三往復になる。
- ツール呼び出し:一つのファイルしか変えないのに、リポジトリ全体を読ませる。
さらに最もよくあるのが、トークン節約の方法をそもそも使っていないのに、プロセスが重いと責めること。
これらを「PDLC はドキュメントが多い」のせいにはできません。ドキュメントは docs/ に静かに置かれ、自分から一つもトークンを燃やしません。燃やしているのは上記の使い方です。
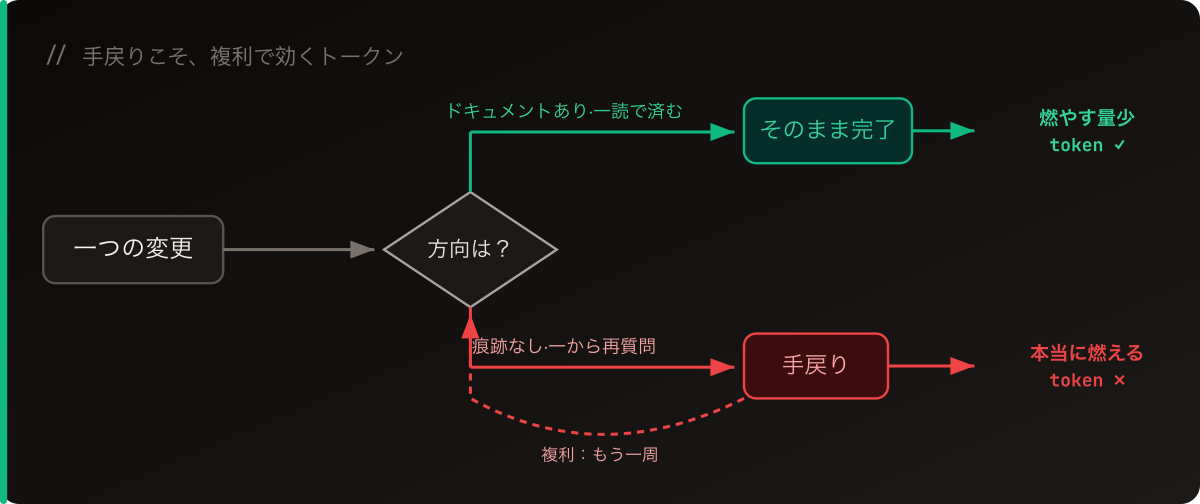
本当にトークンを食うのは手戻り
自分で使ってきた実感では、最大のトークンの浪費はドキュメント生成では決してなく、手戻りです。
方向が間違って書き直す、要件を読み違えて作り直す、直したら別のところが連鎖で壊れて戻る——こうした往復は、一回ごとが実トークンです。PRD を一本生成するのは一度きりの支出;方向違いの手戻りは複利で効いてきます。
重く見える PDLC のプロセスは、まさに「前もって少し多めに書く」ことで「後の手戻りを大きく減らす」取引です。使えば、全体の流れが安定し、最終的な成果物も安定して、行ったり来たりしない。手戻りが減ること自体が、トークンを減らすことです。
だから私の見方はこうです:ドキュメントはコストではなく、資産。設計判断と「なぜそうしたか」を痕跡として残し、遡れる・監査できる。次に AI が引き継ぐとき、ドキュメントを一読すれば分かる——最初から説明し直さなくていい。そこで省けた分が、またトークンです。
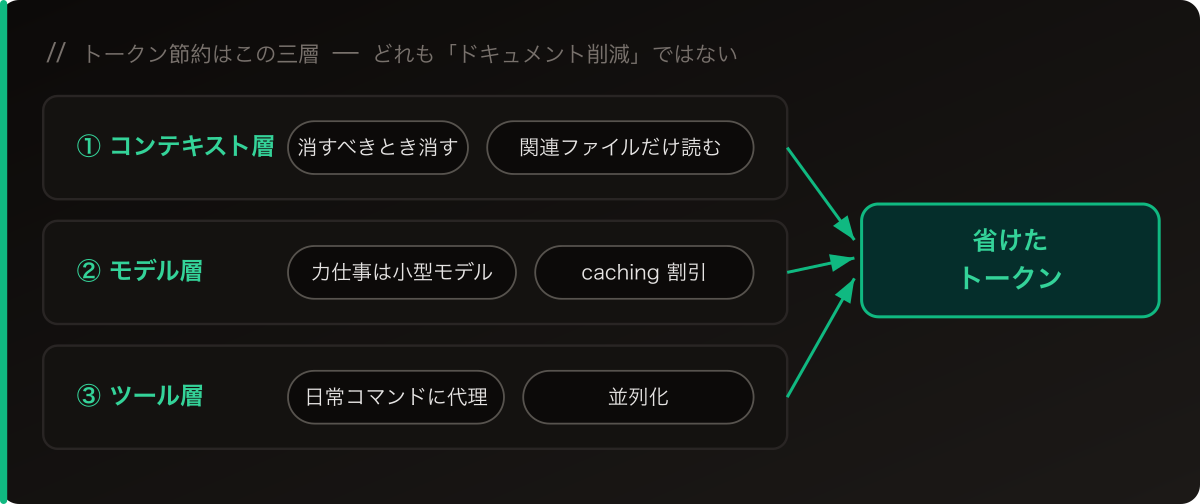
ではトークンはどこで節約すべきか
トークン節約はドキュメントを書かないことではなく、節約すべきところで節約すること。自分のマシンで実際に使っているのは、だいたいこのあたり:
- コンテキストを削る:消すべきときに消す;数万字の履歴を毎ターン引きずらない。
- モデルを階層化:大砲で蚊を撃たない。探索・検索・ファイル読みといった力仕事は安い小型モデルに;本当に頭を使う分析やコード生成にだけ最強の層を出す。
- ファイルを精密に読む:今回の変更に関係する分だけ読む;反射的に「プロジェクト全体を読む」をしない。
- prompt caching:キャッシュにヒットした部分は割引で課金され、しかも 1:1 の線形ではない。うまく使えば節約は明確。
- 日常コマンドにトークンプロキシをかぶせる:
git statusのような高頻度の操作は出力を圧縮する;塵も積もれば。 - 並列化:互いに依存しない作業は一度に投げ、往復を減らす。
どれ一つとして「ドキュメントを減らす」ではありません。
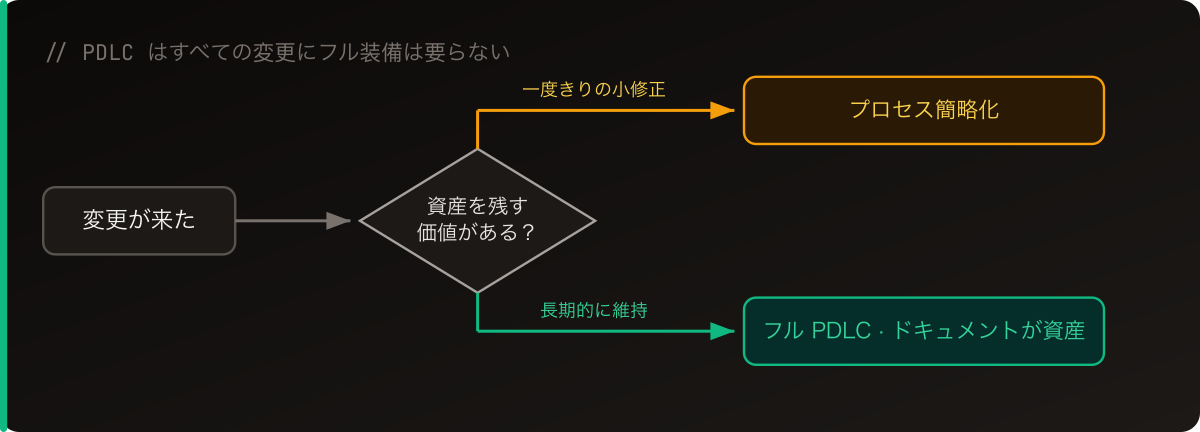
すべての変更にフル装備が要るわけではない
とはいえ、PDLC はどんな変更でもフルスイートを回すという意味ではありません。
一行のバグ修正に、PRD は要るか、設計レビューは要るか?場合による——多くは重いプロセスは不要で、簡略化していい。判断基準はシンプル:この変更は資産を残す価値があるか。あるなら全部回す;一度きりの小さな修正なら、数ステップ削っても誰も責めません。
それから「トークン節約 = お金の節約」は、課金方式ごとに言わないと誤解を招きます:
- 定額の月額サブスクなら、節約するのは枠(クォータ)の余裕——同じお金でより多くの仕事ができる。
- 従量課金の API なら、節約するのは現金そのもの——トークン一つ一つが請求に乗る。
私は両方使っています。まず自分がどちらかを把握すること;それが「トークン節約」の意味を教えてくれます。
最後に
まとめると、ドキュメントが多いこと ≠ トークンを食うこと;本当に節約したいなら、ツールの使い方で節約するのであって、ドキュメントでではない。
一番言いたいこと:ドキュメントは資産であり、コストではない。「ドキュメントを書かず、AI にそのままコードを出させる」でトークンを節約しようとすると、短期的には得に見えても、プロジェクトは遠くまで行けません——痕跡も追跡可能性もなく、二ヶ月後には自分でもなぜこう設計したか説明できない。そのときの手戻りは、節約したドキュメントのトークンよりはるかに多く燃えます。
今日できる一手:トークン節約の方法を使えているか振り返る——コンテキストは削ったか?まだ全部を最強モデルに送って、階層化していないか?削れるコストは削ったか?ついでに、PDLC をちゃんと使えているかも考えてみる。
トークン節約は掘り下げればまだ多くある——モデルの具体的な階層化、コンテキストを消すタイミング、caching の割引をどう効かせるか。次回、一つ選んで深掘りします。
コメント