AI が会話を重ねるほど馬鹿になる?モデルのせいじゃない、そろそろ手を打つ番だ
目次
ある日、AI に機能の続きを実装させていたら、途中から様子がおかしくなりました。返答はどんどん遅くなり、話はちぐはぐ、前に伝えたことをまた聞いてくる。作業は明らかに終わっていないのに「完了しました、休憩していいですよ」と言い出す始末。
最初はモデルの調子が悪い日かと思いました。ところがコンテキストを見ると、もう 80% を超えていた——前に進めることに夢中で、消すのを忘れていたのです。消してから聞き直すと、すぐにシャープに戻りました。速くて、的を射た返答に。
それ以来、これを真面目に扱うようになりました。前の二回はすべて「コンテキストに入る前」に量を絞る話——いわば着工前の話です。今回は着工後、会話の最中にやる二つのこと。同じ作業に何トークン払うか、どれだけ速いか、どれだけ安定するかを、これらが決めます。
一つの会話に、実はノブが二つある
会話の最中に回せるノブは二つ、向きが違います。
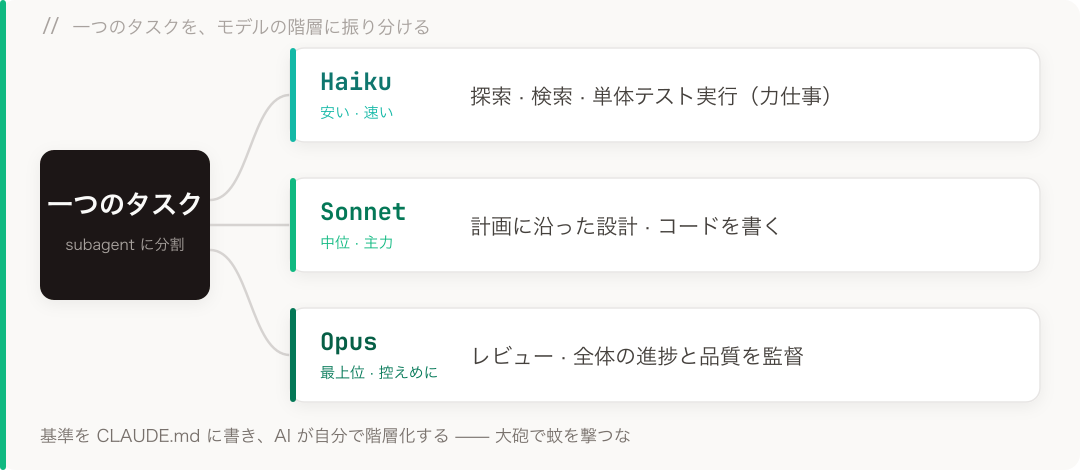
一つは横方向:一つのタスクの中で、違う種類の作業は違う「脳」に振る。探索や検索のような力仕事に最上位のモデルは要らない;本当に頭を使うところ——コードを書く、判断する——にだけ良いモデルを出す価値がある。これをモデル階層化と呼んでいます。
もう一つは縦方向:同じ脳に、一度にどれだけ詰め込むか。コンテキストが太いほど、モデルは毎ターンその一山を計算し直す——遅く、高く、間違いやすい。どれだけ速く膨らむか、いつ消すかを管理するのがコンテキスト管理です。
この二つが節約するものは、二か所に落ちます:従量課金なら現金そのもの、定額月額なら枠の余裕。私は両方使っているので、どちらの手も二重の節約になる。一つずつ見ていきます。
一番高いモデルに全部やらせない
まず横方向から。
あるとき、あるプロジェクトで subagent を一斉に投げようとしていて、まだ従量課金の API、予算が少しきつかった。そこでケチな手を試しました:計画に沿った設計とコード生成は Sonnet に、比較的機械的な単体テストはより安い Haiku に、そして最上位(Opus)は全体の進捗と品質を見るレビュー役に残す。
これが予想以上に効いた。トークンはかなり節約でき、しかも明らかに速くなった——安い小型モデルはもともと速いので、力仕事を任せるとパイプライン全体が軽くなる。一番高い計算力は、一番必要なところにだけ使われる。
この振り分けは固定ではありません。どの作業にどの階層かは、CLAUDE.md(ユーザーレベルもプロジェクトレベルも)に直接書き込み、AI が毎回自分で階層化する——いちいち手で指示しなくていい。ある工程が特に重要だと感じれば、その場で特定のモデルを名指しして担当させることもできる、より精密に。原則は一言:大砲で蚊を撃つな——そしてパチンコで戦車に挑むな。
会話の途中で、頭を整理してやる
次は縦方向——冒頭の「鈍くなる」の張本人です。
コンテキストはひたすら上がっていく。放っておけば、ずっと太り続ける。私のやり方は二本の線:50% あたりで気にし始め、70% でほぼ必ず一度消す。いつものリズムは——手元のタスクが片付いた瞬間、きれいなうちに消す。次の作業が軽装で進めるように、シャープに、速く。
はっきりさせておくと、この二本の線も、冒頭の「80% で鈍る」も、私個人の体感と習慣にすぎません。硬い指標ではない。私はこれで快適ですが、ベンダーや他の人はそう見ないかもしれない——自分のペースで全然かまいません。私はただ提案するだけ:上がりっぱなしで放置するな、と。
消す工程には一つ、触れておくべき罠があります:/compact、/clear、あるいは新しいセッションを開くと確かにコンテキストはすっきりするが、雑にやると大型モデルは直前にやったことをきれいに忘れ、また一から説明し直す羽目になる。私の対処は——消す前に、現在の状況を一筆書かせる:どこまでやったか、次に何をするか、すでに固まっている重要な決定はどれか。この引き継ぎをきちんと書いてから消せば、新しいセッションは一目で追いつき、ぽかんとせずに済む。
正直、この引き継ぎは今まで基本的に外したことがありません。万一うまく繋がらなくても、慌てない——もう一度分析させて結論を出させ、自分で検証して判断すればいい。損は小さい。

ついでに:正確に読めば、抱える量は減る
ここまでは「すでに入ったものをどう管理するか」。実はもう一層、「入ってくるものをそもそも少なく正確に」というのがあります。
これらのプロジェクトには codegraph や claude-mem のようなツールを挂けています。要するに、AI を「いきなりソースを読み、全文をスキャンする」から「核心の数箇所だけ命中させ、過去のセッションで貯めた記憶を引き継ぐ」へ変える——スキャンが減れば、コンテキストに入るものは自然と痩せる。
ここはついでに触れるだけ、展開はしません。一つには、細部を展開するとツールの宣伝になる;二つには、この手のツールはこの二つだけとは限らない——もっと良いものがあるかもしれない、私が使っていなくて知らないだけで。手に馴染むものを知っているなら、それを使えばいい。考え方は同じ:モデルに正確に読ませれば、そんなに多くを抱えて出発しなくて済む。
正直なところ
節約は節約だが、境界を言っておかないと、またいいことずくめの宣伝になってしまう。
モデル階層化で一番心配されるのは:小型モデルは間違えないか?間違えます。でも最後に最上位モデルのレビューを一枚残してあるので、小型モデルのたまの取りこぼしはたいていそこで拾える——今のところ大きな間違いはない。ただしこのレビューは省けない:省けば、階層化で浮いたトークンはいずれ払い戻すことになる。
コンテキスト側も同じ:消しすぎ、引き継ぎが雑すぎれば、やはり何かを失う。だから私は「時間が来たら無心に消す」のではなく、タスクが片付いた直後のきれいな瞬間を選んで消し、ついでに引き継ぎを書く。トークン節約の本意は本当の無駄を切ることであって、連れて行くべき記憶まで一緒に切ることではない。
まとめ:そのままやればいい三つ
実際に手を動かせるのは三つ:
一、一番高いモデルに全部やらせない。力仕事(探索、検索、テスト実行)は安い小型モデルに振り、良い鋼はコード書きと判断に使い、最上位を最後のレビューに残す。基準を CLAUDE.md に書いて、AI が自分で階層化するようにする。
二、コンテキストを上がりっぱなしにしない。自分の線を決める——私は 50% で注意、70% で消す、あなたはあなたの線でいい;タスクが片付くたびに一度消す、太って鈍くなるまで待たない。
三、消す前に引き継ぎを書かせる。どこまで、次は、重要な決定——書いてから compact するか新セッションを開けば、リレーは途切れない。
これを読んで今日できることが一つ:CLAUDE.md を開き、「どの作業にどのモデル」を数行ハードコードし、超えたら消すコンテキストの赤線を自分に設ける。二つ合わせて十分かからないが、以降の会話はずっとあなたのために節約し続ける。
次回はプロンプトそのものを話したい——同じ作業でも、言い方ひとつで AI の仕上がりはかなり変わる;それと複数の agent をどう編成して一緒に働かせるか。興味があれば、コメントで教えてください。
コメント