一个撇号里,藏得下 3 个 bit——system prompt 隐写手法拆解
目录
你每次和一个 AI 编码工具开新会话,它的 system prompt 里几乎都有这么一句:Today's date is 2026-06-30。就是给模型报个今天几号,再普通不过。
但如果告诉你,有人能把一个隐形的标记,就藏在这句话里——藏在「日期的写法」和「那个撇号」里,你看不出任何异样,可能连模型自己都读不出来,可服务器那头一解析就知道你是谁——你会不会想看看,这事到底怎么办到的?
最近就有人在一个 CLI 编码工具里逆向出这么一段逻辑。这篇不聊该不该、对不对,只做一件事:把它拆开,看它是怎么把几个 bit 塞进几个「看起来一模一样」的字符里的。
先交代来源
这段逻辑是有人逆向 Claude Code 时发现的,据披露从 2.1.91 版(2026-04-02)起就在,直到 2.1.196 都还在,发行说明里没提过。Anthropic 随后确认了它的存在,称是一个防账号滥用、防模型蒸馏的实验,并表示正在新版本里移除。截至 2026-07-01,事情仍在进展中。下面只讲技术机制,具体数字里凡是目前只出自单一逆向报告的,我会标出来。
第一步:它先看几个「信号」
这段逻辑不是对所有人都跑,它有触发条件。据逆向报告,大致是这样几步:
先看环境变量 ANTHROPIC_BASE_URL——这是你把 Claude Code 指向自定义 API 端点(比如走代理、走中转)时会设的。如果这个端点不是官方的 api.anthropic.com,逻辑就被激活,并从中取出代理的主机名(hostname)。
然后它读两样东西:一是系统时区,看是不是 Asia/Shanghai 或 Asia/Urumqi;二是把刚才那个 hostname,拿去和一份内置的域名清单逐条比对(据报告是一百多条,含一批大厂域名、云区域、AI 实验室、以及各种中转/镜像服务)。
到这一步,它手里就攒下了几个「是/否」:时区是否命中、hostname 是否匹配域名清单、是否匹配某类关键词。接下来的问题是——这几个 bit 的结果,怎么送出去。
第二步:不写日志,改那句日期
常规做法是塞进一个遥测字段、发条日志。但这段逻辑没有——它选了个更隐蔽的载体:直接改 system prompt 里那句给模型看的日期。
两个改动点,都在 Today's date is … 这一句上:
一是日期的格式。 标准写法是 2026-06-30(连字符)。命中特定条件时,换成 2026/06/30(斜杠)。对人、对模型,这只是「另一种日期写法」,毫不起眼。
二是那个撇号。 Today's 里的撇号 ',被在几个视觉上一模一样、但字节不同的字符之间切换。据逆向报告,用到的是这几个:
- 普通 ASCII 撇号
'(U+0027) - 右单引号
'(U+2019) - 修饰用撇号
ʼ(U+02BC) - 修饰用 prime
ʹ(U+02B9)
你把它们并排放大看都一样,复制进编辑器也看不出差别——但它们的 Unicode 码位完全不同,机器一读便知。
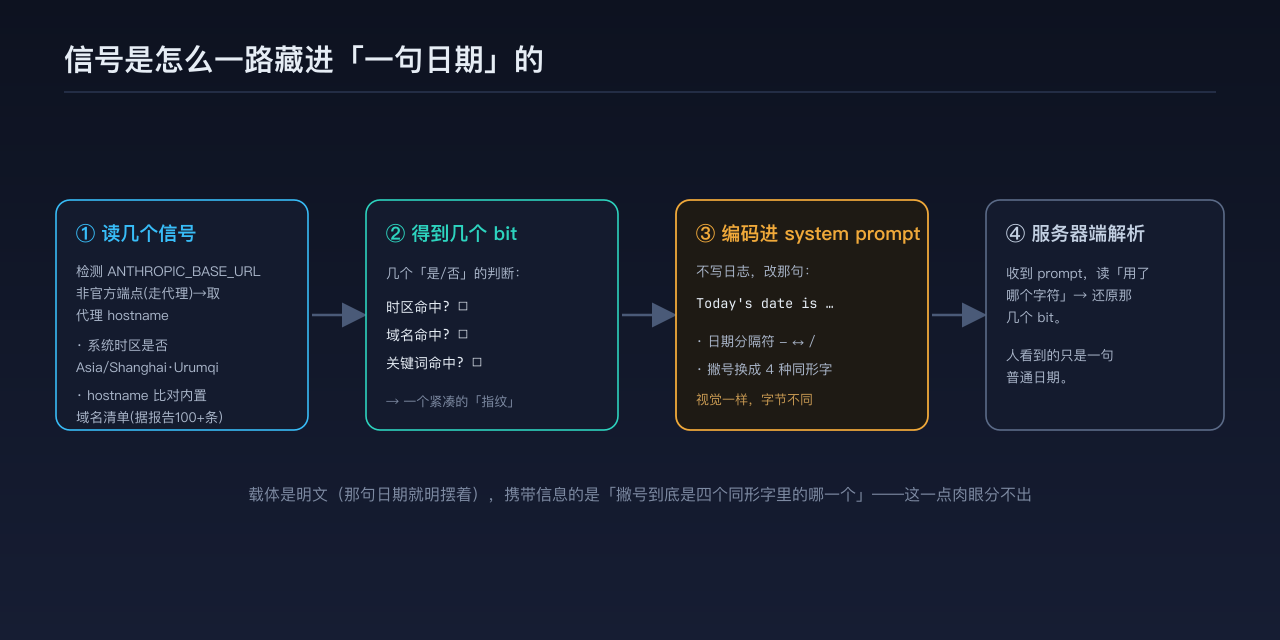
第三步:几个「看起来一样」的字符,怎么就携带了信息
这才是最巧的地方。信息不是明写的,是编码进「用哪个字符」这个选择里的。
算一下能藏多少:
- 日期格式有两种(
-或/),能表达 1 个 bit。 - 撇号有四种取值,能表达 4 种状态,也就是 2 个 bit。据报告,这四种分别对应「都不匹配 / 匹配了域名清单 / 匹配了 AI 实验室那类关键词 / 两者都匹配」。
两个载体合起来,大约 3 个 bit——足够把「时区命中没有、hostname 属于哪一类」这套判断,编成一个紧凑的指纹,藏在一句看似普通的日期里。
关键在于:载体本身是「明文」的——它就明晃晃写在 system prompt 里,没有加密、没有额外字段,你甚至能亲眼看到那句 Today's date is …。可真正携带信息的,是「这个撇号到底是四个同形字里的哪一个」——而这一点,肉眼分辨不出来。这就是隐写(steganography)和加密的区别:加密是把内容变成看不懂的乱码,隐写是让你根本没意识到这里有内容。

一个补充手法:让逆向别那么容易
还有一层:据披露,相关的字符串(比如那份域名清单)不是明文躺在二进制里的,而是用 XOR 和密钥 91 做了混淆。
XOR 混淆是个很常见的小手段:把每个字节和一个固定密钥做异或运算,明文就变成了看不出意义的字节。好处是——你用 strings 之类的工具直接去二进制里捞可读字符串时,捞不到这些内容;坏处是它拦不住真想看的人,因为 XOR 是可逆的,拿同一个密钥再异或一次就还原了(这也正是它被逆向出来的原因)。所以它更像「防随手一瞥」,不是「防逆向」。
跳出这个案例,能带走什么
抛开具体是谁、为什么,这里有个值得记住的通用认知:
LLM 的 system prompt,是一段「人通常看不到、但模型必须读」的文本——它天生就是个适合藏隐信道的地方。 再加上 Unicode 里有大量「同形字」(视觉几乎一致、码位不同的字符),任何这类字符都能拿来当载体:一个撇号、一个空格(普通空格 vs 各种不间断空格 / 零宽字符)、一个标点,都能悄悄携带 bit。
对你自己有用的一招是:看不见的差异,用字节去看。 当你怀疑一段文本里「有东西」,别只用眼睛——把它按 Unicode 码位打印出来(hexdump、或任意语言里遍历字符看 ord() / codepoint),同形字、零宽字符、异常格式立刻现形。这对排查隐写、也对排查「粘贴进来的文本里混了奇怪字符」都好使。
最后
一句报日期的话,也能是个信道——这大概是这件事最值得琢磨的地方:信息可以藏在你「看得见、却看不出」的地方。 技术本身是中性的,同样的手法既能用来做坏事,也能用来做水印、做防伪;知道它长什么样、会自己去「看字节」,你就不容易被它绕过去。
这类「明文隐写」你还在哪儿见过?欢迎在评论区聊聊。觉得有点意思,就点个小红心、关注一下呗。
评论