AI コーディングが高くつく?トークンを 82% 削った(実測データ付き)
目次
前回、こう言いました——トークン節約はドキュメントを削ることではなく、ツールを正しく使うこと。すると聞かれました:で、具体的にどう「正しく」使うのか?
今回は実践、実数付きです。まず見出しの数字:ローカルの rtk gain——トークン節約を集計するツール——を見たら、六千以上のコマンドで 740 万トークン、82% を節約していました。推定ではありません。一件ずつ記録したものです。
では分解します:この 82% がどう節約されるのか。
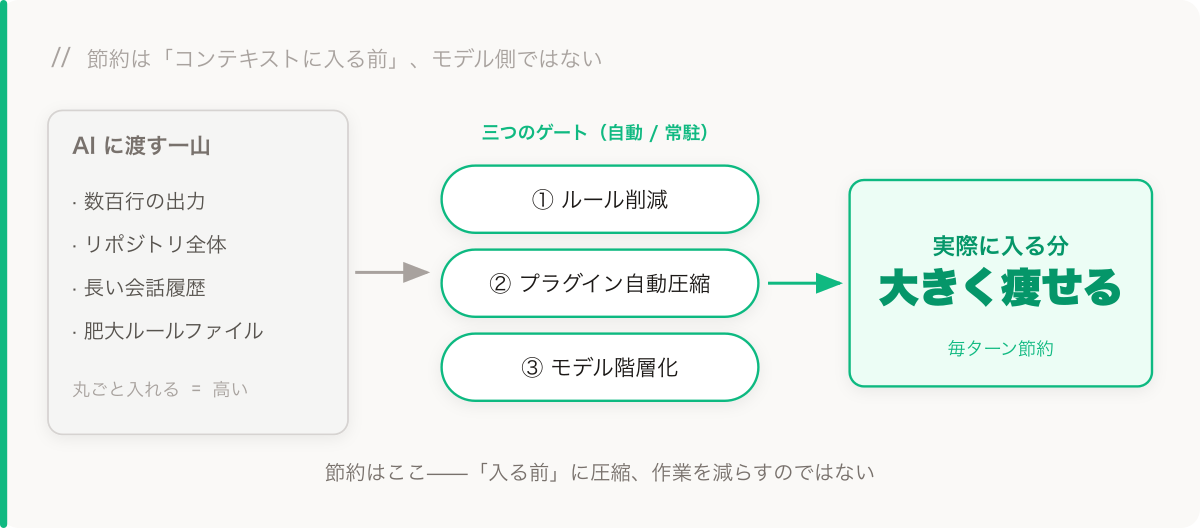
トークン節約は「コンテキストに入る前」で起きる
まず、どこで節約されるか。
トークン消費の大部分は「どれだけ作業したか」ではなく、毎ターン AI のコンテキストにどれだけ詰め込むかにあります。モデルは毎ターン、コンテキスト全体を計算し直す——コンテキストが太いほど、毎ターンが高くつく。
だから核心は一文:コンテキストに入るものを、できるだけ少なく、できるだけ精緻に。
手元に三つのレバーがあります:ルールファイルを削る、プラグインを正しく使う、モデルを階層化する。共通点は一つ——どれも「コンテキストに入る前」に節約し、あなたが作業を減らすわけではない。一つずつ見ていきます。
レバー一:まず CLAUDE.md を痩せさせる
最も見落とされ、最初にやるべきなのが、CLAUDE.md を削ること。
CLAUDE.md(ルールファイル、指示ファイル、呼び方は色々)は、毎回の会話でコンテキストに詰め込まれる。常駐する。書いた行数だけ、毎ターン繰り返しトークンを払う。
自分の CLAUDE.md は一時、長ったらしくなっていました——ユーザーレベルからプロジェクトレベルまで、びっしり注意書き。振り返ると、繰り返しの小言、古くなった取り決め、「書いても書かなくても同じ」な正しい無駄話だらけ。思い切って半分近く削り、本当に毎回使う硬いルールだけ残した。要するに、同じことを三度言っても AI は従順にならず、毎ターン余計にトークンを食うだけ。
この一手で、毎ターン節約できる。常駐するから、一度きりではなく、以降ずっと節約になる。
会話コンテキストも同じ:数万字に膨れた窓は、消すべきときに消す。朝のことを夜まで引きずって毎ターン再計算させない。
レバー二:自動でやってくれるプラグインを入れる
手動だけでは限界がある。コンテキストを自動圧縮するプラグインをいくつか入れています。データが語ります。
RTK(Rust Token Killer)——コマンドプロキシ。AI に git status、ps aux、テストを走らせると、その出力は数百〜数千行、丸ごとコンテキストに入れると非常に高くつく。RTK は AI に届く前に圧縮する。私の rtk gain:六千以上のコマンドで 740 万トークン、82% 節約。一番効くのは高頻度で栄養のない出力——ps aux の数百行のプロセス一覧、AI が読んでも得るものはなく、99% 節約;テストログ 88%;ファイル読み込みも平均 2 割引き。
claude-mem——記憶プラグイン。セッションをまたぐ作業を構造化記憶に圧縮し、次回プロジェクト背景を説明し直さなくていい。本セッション実測 86% 節約。全自動、ほぼ触りません。
codegraph——コードグラフ。プロジェクトの関数・型・呼び出し関係のインデックスを作る。AI がある関数を探すとき、ファイルを大量に読まず、インデックスを引くだけ。私の aitm プロジェクトでは 246 ファイル、3562 シンボル をインデックス化。「インデックスを引く」と「246 ファイルを頭から読む」——差は小さくない。前者は本の目次をめくるよう、後者は一つの質問に答えるために本を丸ごと暗記するよう。
この三つの共通点:自動、常駐、コンテキストに入る前に節約。入れたらほぼ忘れる——ずっと節約し続けてくれる。

レバー三:一番高いモデルで全部やらない
最後、モデル階層化。
探索・検索・ファイル読みといった力仕事は安い小型モデルに;本当に頭を使うコード生成や判断にだけ最上位を出す。特に subagent を投げるとき——一つのタスクを複数に分け、力仕事は小型モデルに。これが枠を節約する主戦場。
この判断基準を CLAUDE.md に直接書き込み、AI が毎回自分で階層化する——いちいち指示しなくていい。
これは Claude Code に限りません。どの AI プラットフォームでも理屈は同じ:各モデルの能力と値段を把握し、仕事に応じた階層を使い、高価な計算力を要所に使う。
もう一手:繰り返し入る分を割引にする
上の三つのレバーはどれも「コンテキストに入る量を減らす」もの。もう一つ、性質の違うのが——prompt caching。量は減らさず、繰り返し入る分を割引で課金させる。
システムプロンプト、変わらないルールファイル、固定のプロジェクト背景——毎ターン同じものは、初回は全額、以降はキャッシュヒットで割引。しかも線形の割引ではなく、うまく使えば節約は明確。
コツはキャッシュ可能な部分を変え続けないこと:固定・不変のものをコンテキストの前に置いて安定させ、毎ターン変わるものを後ろに。構造が安定するほどキャッシュヒット率が上がり、割引を満額享受できる。
これには RTK のような実測値はありません(節約は課金側で、トークン数ではない)。でも原理は単純、コストはほぼゼロ——当たり前に使う価値があります。
正直なところ:これはタダ飯ではない
コストも言っておかないと、ただの宣伝になる。
codegraph はまずインデックスを作る必要があり、大きなプロジェクトでは時間がかかる;claude-mem の記憶はたまに少しずれて思い出すので、気をつけておく;CLAUDE.md の圧縮にも限度がある——本当に毎回必要な硬いルールまで削ると、AI が脱線して手戻りし、小さな得で大きな損をする。
それと「トークン節約」を作業を減らすことと勘違いしないこと。むしろ逆——削るのは「本来省くべき無駄」:繰り返しのコンテキスト、リポジトリ全読み、大砲で蚊を撃つこと。やるべき仕事は依然としてやる。
節約が何を意味するかは課金方式次第(前回触れた):定額月額なら枠の余裕、従量課金なら現金そのもの。両方使っているので、これらの方法は私には二重の節約。
最後に
あの 82% に戻ります。魔法ではなく、上の小さなことの積み重ね:ルールファイルを削り、自動プラグインをいくつか入れ、モデルを階層化する。一つ一つは地味でも、積み重なれば六千以上のコマンドで 740 万トークンの節約。
今日できることが二つ、十分で始められます:
一つ、CLAUDE.md を開き、繰り返し・古い・書いても同じものを削り、何行まで減らせるか見る。
二つ、RTK を入れ、数日走らせ、その gain がどれだけ節約したか見る——その数字におそらく二度見します。
トークン節約はひとまずここまで。次回はモデル階層化の細部を掘り下げたい:どのモデルにどの仕事を割り当てるか、AI が自分で階層化するよう CLAUDE.md をどう書くか。それとコンテキスト管理の細部——いつ消すか、どう精密に読むか。興味があれば、コメントで教えてください。
コメント