AI 编码越用越贵?我把 token 砍掉了 82%(附实测数据)
目录
上一篇我说,省 token 不在砍文档,在把工具用对。有人接着问:那到底怎么用对?
这篇上实测。先甩个数字:我翻了下本地的 rtk gain——这是个统计 token 节省的工具——六千多条命令,累计省下 740 万 token,82%。不是估的,是它一条条记下来的。
这篇就拆开讲:这 82% 是怎么省出来的。
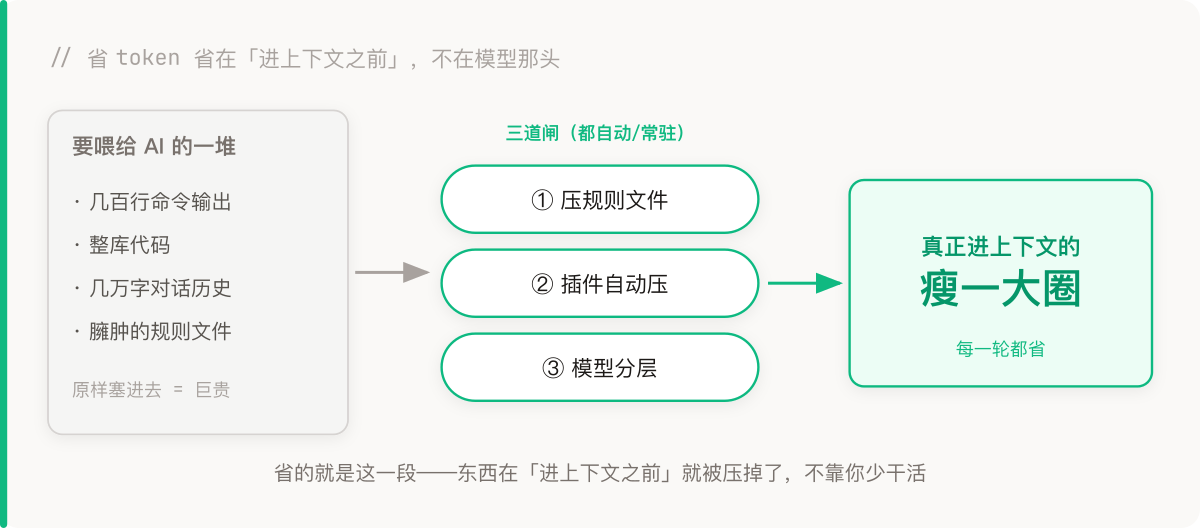
省 token,省在”进上下文之前”
先说清楚省在哪。
省 token 的大头,不在你”干了多少活”,在每一轮对话往 AI 上下文里塞了多少东西。模型每轮都要把整个上下文重新算一遍——上下文越肥,每一轮越贵。
所以核心就一句话:让进上下文的东西尽量少、尽量精。
我手上三个抓手:压规则文件、用对插件、模型分层。它们有个共性——都省在”进上下文之前”,不靠你少干活。下面一个个拆。
抓手一:先把你的 CLAUDE.md 压瘦
最容易被忽略、又最该先做的,是压你的 CLAUDE.md。
CLAUDE.md(规则文件、指令文件,叫法不一)是每次对话都会被塞进上下文的东西。它常驻。你写了多少行,每一轮就重复付多少行的 token。
我自己的 CLAUDE.md 一度写得又臭又长,从用户级到项目级,密密麻麻叮嘱了一大堆。后来回头一看,里头全是重复的唠叨、过时的约定,和一堆”写了跟没写一样”的正确废话。狠心砍掉将近一半,只留真正每次都用得上的硬规则。说到底,同一句话叮嘱三遍,AI 也不会更照办,纯是每轮多花 token。
就这一下,每一轮对话都省。因为它常驻,省的不是一次,是往后每一次。
对话上下文同理:一个聊到几万字的窗口,该清就清,别让早上的事拖到晚上还在每轮重算。
抓手二:装几个自动干这事的插件
光靠手动还不够。我装了几个自动压上下文的插件,数据说话。
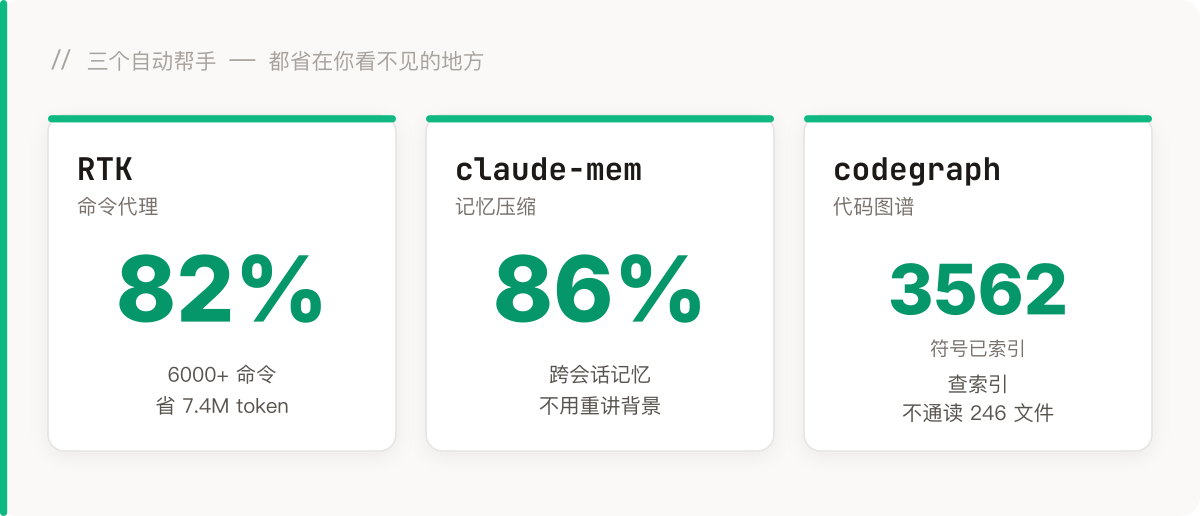
RTK(Rust Token Killer)——命令代理。你让 AI 跑 git status、ps aux、跑测试,那些输出动辄几百上千行,全塞进上下文巨贵。RTK 在输出进 AI 之前就把它压掉。我的 rtk gain:六千多条命令省了 740 万 token、82%。省得最狠的是那些高频又没营养的输出——ps aux 几百行的进程列表,AI 看了纯属遭罪,省 99%;测试日志省 88%;连读文件平均也省两成。
claude-mem——记忆插件。把跨会话的工作压成结构化记忆,下次不用重新跟它解释项目背景。本会话实测省了 86%。全自动,基本不用我管。
codegraph——代码图谱。它给整个项目的函数、类型、调用关系建了个索引。AI 要找某个函数,查索引就行,不用把一堆文件通读一遍。我的 aitm 项目,它索引了 246 个文件、3562 个符号。”查索引”和”把 246 个文件从头读一遍”,差的不是一星半点——前者像翻书的目录,后者像为了回答一个问题先把整本书背下来。
这三个的共性:自动、常驻、省在进上下文之前。装好基本就忘了它,它一直在帮你省。
抓手三:别用最贵的模型干所有活
最后一个,模型分层。
探索、搜索、读文件这种粗活,交给便宜的小模型;真正要动脑的写代码、做判断,才上最强那档。尤其派 subagent 的时候——一个任务拆几个子 agent,粗活那些用小模型,这是省额度的主战场。
我把这套判断标准直接写进了 CLAUDE.md,让 AI 每次自己照着分,不用我每回交代。
这事也不限于 Claude Code。换任何 AI 平台,道理一样:摸清每个模型的能力和价钱,该用哪档用哪档,把贵的算力用在刀刃上。
还有一招:让重复进去的部分打折
前面三个抓手,都是在”减少进上下文的量”。还有一个角度不一样——prompt caching,它不减量,是让重复进去的部分按折扣计费。
系统提示、不变的规则文件、固定的项目背景,这些每轮都一样的东西,第一次进去算全价,之后命中缓存就打折——而且不是线性的折扣,用好了省得明显。
诀窍是别让该缓存的东西老变:固定不变的放上下文前面、稳住,每轮变动的放后面。结构越稳,缓存命中率越高,折扣吃得越满。
这招我没有像 RTK 那样的实测数字(它省在计费这头,不在 token 数量上),但原理简单、几乎零成本,顺手就能用上。
几句实话:这不是免费午餐
得把代价也说清楚,不然就成种草文了。
codegraph 要先建索引,项目大了索引也花时间;claude-mem 的记忆偶尔召回得不那么准,得自己留个心眼;压 CLAUDE.md 更有个度——把真正每次都要用的硬规则也压没了,AI 跑偏返工,那是捡芝麻丢西瓜。
还有,别误会”省 token”是让你少干活。恰恰相反,它砍的是”本来就该省的浪费”——重复的上下文、通读整库、大炮打蚊子。活该干的还得干。
省下来意味着什么,得看你怎么计费(上篇讲过):包月省的是额度窗口,按量省的是真金白银。两种我都在用,所以这些方法对我是双重的省。
最后
绕回开头那个 82%。它不是什么神技,是上面这些小事垒出来的:压规则文件、装几个自动插件、分层用模型。每一项单看不起眼,叠在一起,就是六千多条命令省下的 740 万 token。
今天你能做两件事,十分钟就能开始:
一,打开你的 CLAUDE.md,把重复的、过时的、写了等于没写的删掉,看看能从多少行压到多少行。
二,装个 RTK,跑几天,看它的 gain 给你省了多少——那数字大概率会让你愣一下。
省 token 这事我先聊到这。下次想聊聊,模型分层的细节:怎么判断哪个模型该干什么活,怎么写 CLAUDE.md 让 AI 照着分。还有上下文管理的细节,什么时候该清、怎么精准读文件。感兴趣的话,留言告诉我。
评论