AI 越聊越笨?不是模型菜,是需要上点手段了
目录
那天我让 AI 接着写一个功能,写着写着不对劲了:回答越来越慢,话也说得颠三倒四,前面交代过的东西它又问一遍,明明活没干完,它却跟我说”做完了,可以休息一下了”。
我一开始还以为是模型今天状态不好。回头一看上下文,已经撑到 80% 多了——我光顾着往下推,忘了清。清完再问,立刻就顺了,回答又快又在点子上。
那次之后我才认真对待这件事:前两篇我讲的都是怎么在”进上下文之前”把量压下去,那是开工前的事;这篇要讲的是开工之后、一场会话进行当中的两件事——它们决定了同样的活,你花多少 token、跑多快、稳不稳。
同一场对话里,其实有两个旋钮
会话进行中能动的旋钮有两个,方向不一样。
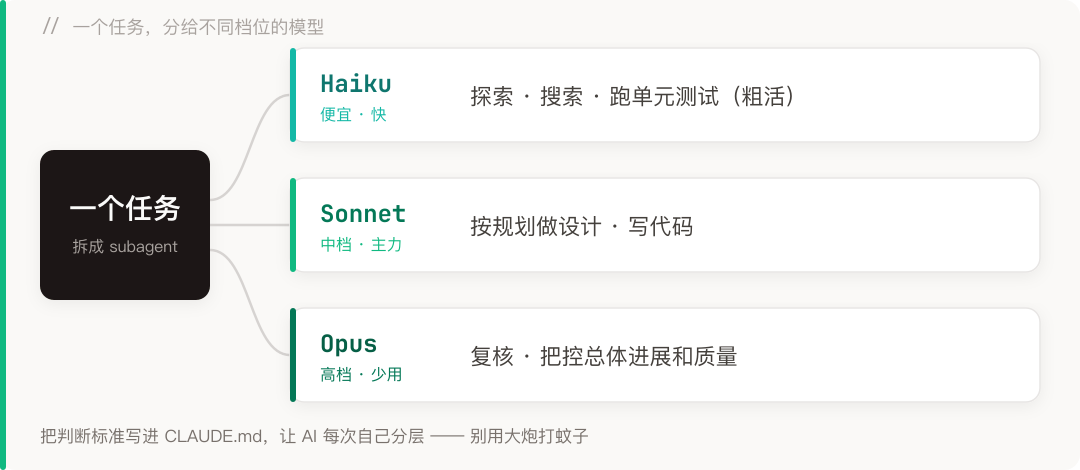
一个是横向的:一个任务里,不同的活该交给不同的”脑子”。探索、搜索这种粗活,没必要上最贵的模型;真正要动脑子写代码、做判断的地方,才值得把好模型派上去。这件事我叫它模型分层。
另一个是纵向的:同一个脑子,一次到底塞多少东西进去。上下文越胖,模型每一轮都要把这一大坨重新算一遍,又慢又贵,还容易出岔子。管住它涨多快、什么时候清,这件事是上下文管理。
这两件事省下来的,落点也分两头:按量计费时省的是真金白银,包月时省的是额度窗口。我两种都在用,所以这两招对我是双份的划算。下面分开说。
别让最贵的模型干所有的活
先说横向那个。
有一次我在一个项目里准备派一批 subagent 干活,当时还是走 API 按量计费,预算有点紧。我索性试了个穷办法:按规划做设计、生成代码这部分交给 Sonnet,单元测试这种相对机械的活丢给更便宜的 Haiku,最后留高级模型(Opus)把控总体进展和质量,做一次复核。
结果出乎意料地好。token 省了不少,速度还明显快了一截——便宜的小模型本来就跑得快,粗活交给它,整条流水线都轻了。最值钱的算力只花在最该花的地方。
这套分法不是死的。哪种活配哪档模型,我直接写进了 CLAUDE.md(用户级、项目级都有),让 AI 每次自己照着分,不用我每回手动指派。要是某个环节我觉得特别关键,也可以临时点名让某个模型专门来做,更精准。原则就一句:别用大炮打蚊子,也别拿弹弓去轰坦克。
聊到一半,记得给它清清脑子
再说纵向那个,也就是开头那场”降智”的正主。
上下文这东西会一路往上涨,你不管它,它就一直胖下去。我自己的做法是给它设了两条线:到 50% 左右我就开始留神,到了 70% 基本就一定清一次。通常的节奏是——手头这项任务一做完,就趁着干净利落清理一遍,让接下来的工作尽量轻装上阵,又准又快。
要说清楚的是,这两条线、还有开头说的”80% 就降智”,都只是我自己的体感和操作习惯,不是什么硬指标。我这么用着顺手,但厂家和别人未必这么看,你完全可以按自己的节奏来。我只是建议:别让它一直涨上去不管。
清理这一步有个坑,必须提一句:/compact、/clear 或者干脆开个新会话,确实能让上下文清爽,但弄不好大模型会把之前干的事忘得一干二净,你又得从头解释。我的办法是——清之前,先让它把当前的工作情况记一笔:干到哪了、下一步要做什么、有哪些已经定下来的关键决策。把这段交接写好了再清,新会话上来扫一眼就能接上,不至于一脸懵。
说实话这招我用到现在,接力基本没翻过车。万一真有一次接不上,也不慌——让它重新分析一遍、给我一个结论,我自己验证判断一下就是了,损失不大。

顺带一提:读得准,才带得少
上面说的是”已经进来的东西怎么管”。其实还有一层是”让进来的东西本身就少而准”。
我这几个项目里都挂着 codegraph 和 claude-mem 这类工具。简单说,它们让 AI 从”一上来就读源码、全文扫一遍”变成”直接命中核心那几段、续上之前几次会话攒下的记忆”——少扫一大圈,进上下文的东西自然就瘦了。
这里我只是顺带提一下、不展开。一来细节展开就成了给工具站台;二来这类工具市面上未必只有这两个,没准还有更好用的,只不过我没用上、不知道而已。你知道趁手的,照用就行,思路是相通的:让模型读得准,它就不用带那么多东西上路。
几句实话
省归省,得说清楚边界,不然又成了一篇只报喜的稿子。
模型分层最容易让人担心的是:小模型会不会干错?会的。但我留了高级模型在最后复核这一道,小模型偶尔出点岔子,基本都能在复核时兜住,到现在没出过特别大的错。前提是这道复核不能省——省了它,分层省下来的 token 迟早赔进去。
上下文那边也一样:清得太勤、交接写得太潦草,照样会丢东西。所以我不是”到点就无脑清”,而是挑一个任务刚做完、最干净的时间点清,顺手把交接记好。省 token 的本意是砍掉真正的浪费,不是把该带的记忆也一起砍了。
复盘:三条照着做就行
这篇能落地的就三条:
一,别用最贵的模型干所有活。把粗活(探索、搜索、跑测试)分给便宜的小模型,好钢用在写代码和做判断上,留一档高级模型在末尾复核。判断标准写进 CLAUDE.md,让 AI 自己分。
二,别让上下文一直涨。给自己定条线——我是 50% 留神、70% 必清,你可以定你自己的;一个任务做完就清一次,别等它撑到开始降智才动手。
三,清之前先让它写一段交接。干到哪、下一步、关键决策,记好了再 compact 或开新会话,接力就不会断。
你今天读完就能做的一件事:打开你的 CLAUDE.md,把”什么活用什么模型”写死成几条规则;再给自己定一条上下文红线,超了就清。两件事加起来不到十分钟,但接下来每一场对话都在替你省。
下一篇我想聊聊提示词本身——同样一件事,话怎么说,AI 干出来的成色差很多;以及多个 agent 怎么编排着一起干活。感兴趣的话评论区告诉我。
评论