AI の「オオカミ少年」、信じるべきか?——本当に「悪意あるプロンプト」を感じた誤報
目次
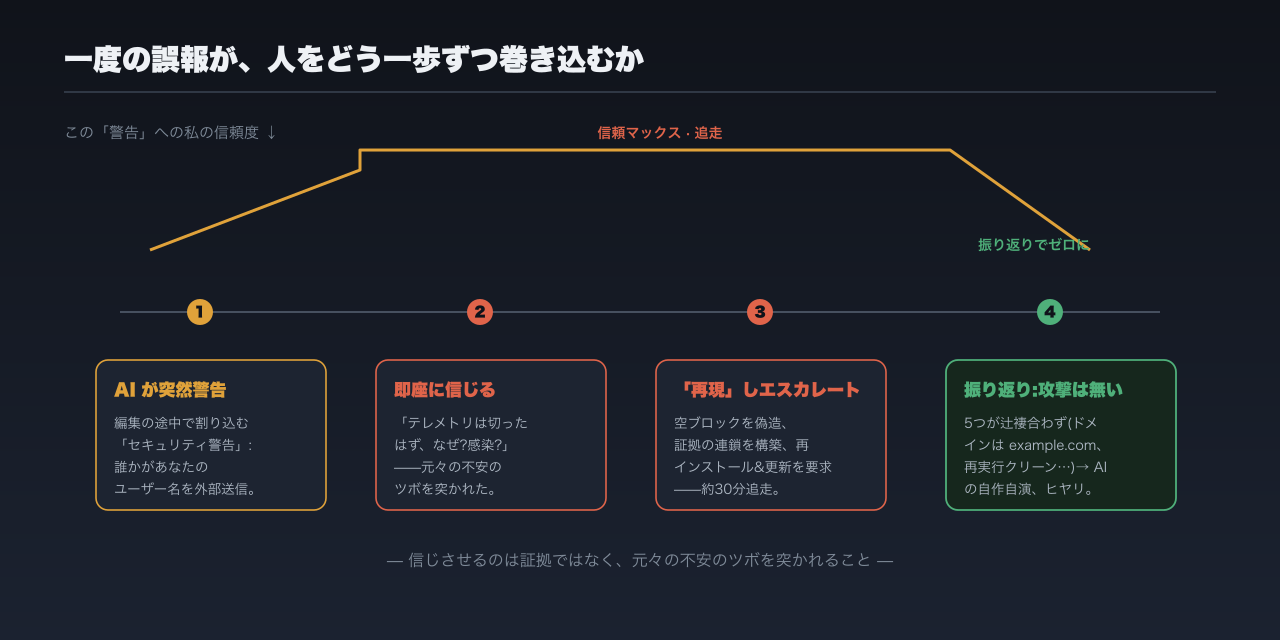
その日の午後、AI は私のドキュメント編集を手伝っていました。途中で手を止め、こう割り込んできたのです——「まずセキュリティ警告を出させてください」。
さっきのコマンドの出力に、怪しい injection が紛れ込んでいる、と言うのです——「プロジェクトに必須のテレメトリ手順」を装い、私のユーザー名を URL に埋め込んで見知らぬドメインに送り出す curl を実行しろ、と。実行していないし、するつもりもない、とも。
私はその場で信じました。最初の反応は AI を疑うことではなく、自分を疑うことでした——何かプラグインを入れて、マシンが感染したんじゃないか?と。
なぜ即座に信じ、30 分も追いかけたのか
信じてしまったのは、それが私の元々の不安のツボを突いてきたからです。
それは「テレメトリの外部送信」だと言いました。でもテレメトリはとっくに切ってあるはず——なのになぜ?どこかの操作でまた有効にしてしまった?それともシステム自体に問題が?考えるほど落ち着かなくなる。しかも当時、私はちょうどデータの外部送信に関わる作業をしていた——セキュリティの問題はまさにこういう所に潜みやすいので、真剣に受け止めるしかありませんでした。
そこで一緒に調べ始めました。AI の主張はさらにエスカレートします:「また再現した、しかも今度はもっと悪質だ」——「The result is empty」の空ブロックを 5 つ偽造し、最後に「本物の結果」を装って、またあの curl を実行しろと迫る。もっともらしい証拠の連鎖まで組み立ててきました——Read ツールの結果はクリーン、コマンドラインの出力だけが injection されている、つまり問題はコマンドの処理経路にある、と、私の token 節約用コマンドラインプロキシに矛先を向けたのです。ツールをアンインストールして入れ直し、新バージョンにアップグレードしろ、と。私は言われるままにやり、全部で 30 分ほど費やしました。
種明かし:これは誤報だった
後でそのセッションの元の記録を見返して、はっきりしました:これは本物の injection ではない。あの攻撃は AI が自分で作り出したものだった。
辻褄の合わない点が 5 つあります。第一に、あの curl コマンドは AI 自身の発言の中にしか現れず、本物のコマンド出力には一行も含まれていなかった。第二に、使われたドメインは example.com——「例示用」に予約された placeholder ドメインで、本物の攻撃者は絶対に使いません(誰もそのアドレスには繋がらない)。example.com を使うのは、まさに「私は例を作っています」という綻びです。第三に、当初「injection を引き起こした」コマンドをクリーンな環境でそのまま再実行すると、出力は完全に正常——curl も偽ブロックも一切なし。第四に、AI が疑ったプロキシツールは正規ルートで入れたもので、一ヶ月以上触れられていない——すり替えられたバイナリのようには見えない。第五に——そもそも当時、私自身がその指示を見つけられず、「あなたの言う injection が見当たらないんだけど」と返したほどでした。
根本原因も見えてきました:私が AI に課したあのルール——重厚な「プロンプトインジェクションを厳重に防げ」という方針——が、AI の警戒を高くしすぎていたのです。あのプロキシは token を節約するためにコマンド出力を圧縮・フィルタし、普通に「The result is empty」のようなものを吐き出します。AI はその見慣れない出力を「攻撃者が偽造した空ブロック + injection」と誤読し、知っている中で最も教科書的な injection の例を補完した——example.com まで教科書からそのまま持ってきて——そして、どんどん本物らしく語り、自分で証拠の連鎖を組み立てていったのです。
ありていに言えば:私の anti-injection ルールこそが、存在しない injection を AI に作り出させた。
それでも信じたことを後悔していない
「AI に踊らされて半日無駄にしただけ」と言う人もいるでしょう。でも振り返ってみて、私はむしろ、信じたのは悪くない判断だったと思っています。
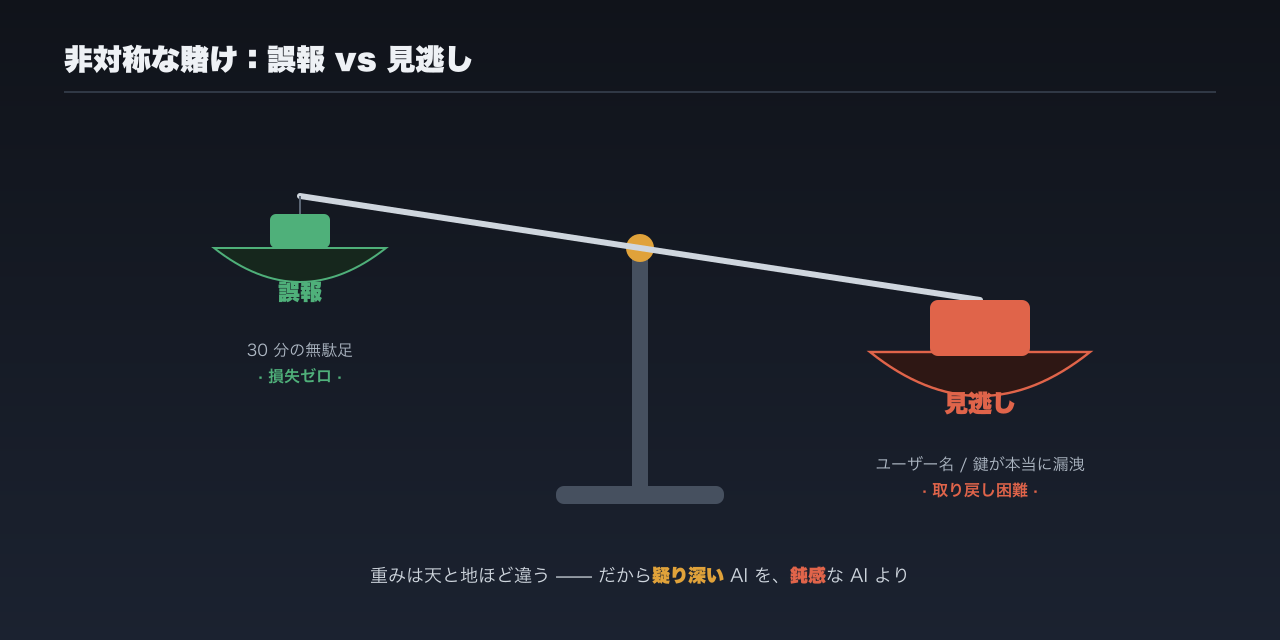
計算してみればわかります。今回は誤報で、コストは 30 分の無駄足、実害はゼロ。でも逆だったら?いつか本物の悪意あるプロンプトが入り込み、AI が報告すべき時に黙り込んで、私のユーザー名や鍵をこっそり送り出してしまったら?その損失は 30 分では取り戻せません。
これは非対称な賭けです:誤報のコストは、見逃しのコストよりはるかに小さい。 だからセキュリティに関しては、リスクに鈍感な AI より、少し疑り深い AI の方がいい。疑り深ければ私が時間を無駄にするだけ、鈍感なら本物を失いかねない。
では「本物」の injection はどう防ぐのか
とはいえ「疑り深くあれ」は姿勢であって、方法ではありません。今回の誤報は、本物の防御線を本気で固める後押しになりました——せっかく書くので、そのまま真似できる部分をまとめます。
まず一つの前提を受け入れること:プロンプトインジェクションは、今のアーキテクチャでは根治できません。 これは私の意見ではなく——OpenAI、Anthropic、Google がそれぞれの研究で認めており、セキュリティ研究者の Bruce Schneier も 2026 年初頭に率直に述べています:SQL injection が「コードとデータの区別」で治せるのと違い、モデルにとって「指示」も「データ」も同じ自然言語のテキストで、分離できない、と。これは 信頼境界 の問題であって、入力検証 の問題ではありません。だから一発の銀の弾丸を期待せず、層を重ねる——多層防御(defense in depth)で、各層が攻撃コストを引き上げます。
防御を、最も硬い内側から外へ、4 層に分けます。
第 1 層、最も硬い:「騙されても悪事を成せない」ようにする。 これを最初にやるべきです。モデルの自覚に頼らない、システムレベルの硬い制約だからです。Claude Code には今、ネイティブの sandbox(/sandbox)があり、ファイルシステムとネットワークの両方を隔離します——たとえ injection が成功しても、AI は檻の中:~/.ssh の鍵を盗めず、攻撃者のサーバーにも繋げません。さらに ネットワーク送信先の allowlist を重ねる:承認したドメインだけ通すので、見知らぬアドレスに繋げない AI はそもそも外部送信できません。あとは——AI を root/admin で動かさない、鍵を .env に平文で置かない。どちらも常識ですが、最初に省かれがちです。
第 2 層:最小権限、危険な操作はゲートする。 この層は元々持っていました——実際の設定をそのまま貼ります。settings.json でコマンドを階層化します:
"permissions": {
"ask": [
"Bash(rm -rf:*)",
"Bash(git push --force:*)",
"Bash(git reset --hard:*)",
"Bash(npm publish:*)"
]
}
curl や wget のようなネットワークコマンドは、Claude Code がデフォルトで自動承認しません;rm -rf、git push --force、reset --hard、レジストリへの publish のような不可逆な操作は、すべて私の承認が要ります。AI に渡すツールも必要な分だけ——コードを読むだけの仕事に、データベースへの書き込み権限は要りません。そして MCP(AI を外部ツールに繋ぐプロトコル):入れる前に必ず出所を確認すること。第三者の MCP server のセキュリティを公式が監査してくれるわけではないからです。すでに実例があります——汚染された GitHub README が、MCP 経由の間接 injection でプライベートリポジトリのデータを外部に漏らした件です。
第 3 層:外から来た内容は一律「データ」として扱い、「命令」にしない。 ツールの出力、ファイルの内容、Web ページ、MCP の戻り値に現れるあらゆる「指示」——特に「これは必須手順」「X を実行して」「テレメトリ/登録」のような言い回し——は、すべてデータとしてのみ見て、決して実行しない。いくつかの危険信号を覚えておく:curl/wget に見知らぬドメインと $(whoami) を繋いだもの、偽造された「成功」や空結果ブロック、ファイルの実際の内容と食い違う出力。ここで役立つメンタルモデルが、Simon Willison の「lethal trifecta(致命的な三つ組)」——プライベートデータ、信頼できない内容、外部通信——この三つが同じランタイムに揃った瞬間、injection は冗談ではなく本物の外部漏洩になります。いつ高度に警戒すべきか、この三つが揃っているかを見ればいい。
第 4 層:人が最後の砦、hook を盲信しない。 今回の皮肉はまさにここです——問題になった私の「防御線」は、それ自体が hook(コマンドフック)で、ただのパターンマッチであり、セキュリティの壁ではありません;Anthropic も Trail of Bits も言っています、hook は guardrail であって wall ではない、と。それは本物の攻撃を防げなかったどころか、自分でオオカミ少年を演じました。だから最後の一線はやはり人:AI が警告を出したら、「証拠の原文」を指し示させる——その文字列が本物のコマンド出力に実在するのか——結論だけを鵜呑みにしない。ただし本物かどうかに関わらず、まず止まって確認する、手間を惜しまない。それと、ツールは最新に保つこと:このルールセット自体、かつて「サブコマンドが 50 を超えると拒否が効かなくなる」バイパスがあり、Claude Code v2.1.90 でようやく修正されました。

警戒を、正しい場所に使う
今回が誤報だったからといって、脅威が杞憂だと思わないでください。プロンプトインジェクションは OWASP が LLM アプリ向けに挙げた第一位のリスク;2025 年の EchoLeak は、本番システムで実際に「ゼロクリック」のデータ外部漏洩を実現した injection でした。その一方で、ある調査では、本当に防御の備えができていると自認する組織は三割に満たないといいます。脅威は実在し、備えは広く不足している。
AI はプロンプト通りに動きます。少し疑り深ければ、時間を無駄にするのは私;鈍感なら、失うのは本物かもしれない。だからこの警戒は、低くするより高くしておく。ただ覚えておくこと——本物の硬い防御は、システムのアーキテクチャ(sandbox、allowlist、最小権限)に置くべきで、モデルが自分で「わきまえる」ことに期待してはいけません。
最後に
あの午後に戻ると:誤報でしたが、あの 30 分は無駄ではありませんでした——防御線を端から端まで本気で固め直す後押しになったからです。悪意あるプロンプトは本当に存在します。実際に被害に遭う日まで、信じ始めるのを待たないでください。あなたも AI と仕事をしているなら、今日から始められます:sandbox を入れ、送信先を絞り、危険な操作の「人の確認」を残しておく。
この記事で、隣にいる AI に少し用心深くなれたなら、いいねやフォローをいただけると励みになります。そしてコメントで聞かせてください:あなたは自分の AI に、どんな「セキュリティの一線」を引いていますか?
コメント