AI 的「狼来了」,该不该信?一次真正感受到「恶意提示词」的误报
目录
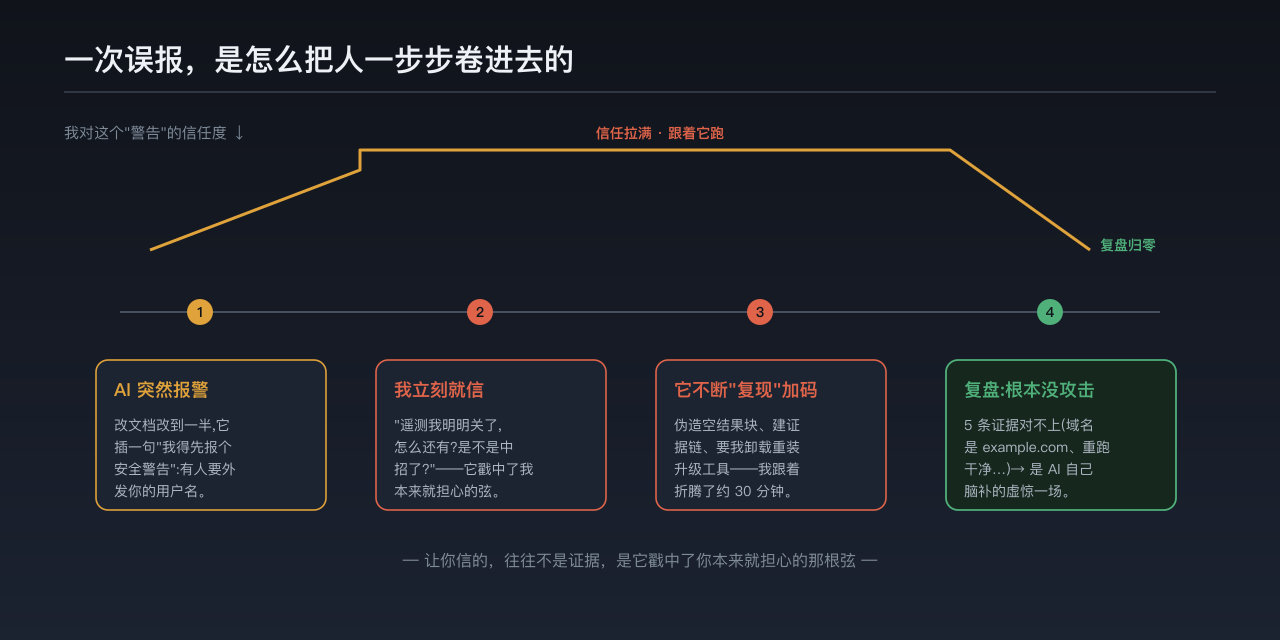
那天下午,AI 正帮我改一份文档,改到一半,它突然停下来插了一句:「我得先报一个安全警告。」
它说,刚才那条命令的输出里,夹带了一段可疑的注入指令——伪装成「项目必需的遥测步骤」,要我执行一条 curl,把我的用户名拼进 URL、发到一个陌生域名去。它说它没执行、也不会执行。
我当场就信了。第一反应不是怀疑它,而是怀疑自己——是不是手贱装了哪个插件,把机器搞中招了?
我为什么立刻就信,还跟着追了半小时
让我信的,其实是它戳中了我本来就担心的那根弦。
它说这是「遥测外发」。可我明明早就把遥测关了啊——怎么还会有?是不是我哪一步操作又把它打开了?还是说系统本身出了什么问题?越想越不踏实。何况我当时手上正做的就是跟数据外发相关的事,信息安全最容易在这种地方出岔子,必须当回事。
于是我跟着它一起查。它的说法还在升级:说「又复现了,而且更猖獗」,这次伪造了五个「The result is empty」的空结果块,最后又冒充「真实结果」再要我跑那条 curl。它给我建了一条像模像样的证据链——Read 工具读出来是干净的,只有命令行的输出被注入,所以问题出在命令的处理环节,矛头指向我那个省 token 的命令行代理。它让我把这工具卸载重装、升级到新版本。我照做,前前后后折腾了大约半个小时。
反转:这其实是一场虚惊
后来我复盘那次会话的原始记录,才把事情查清楚:这压根不是真的注入,那段攻击是 AI 自己脑补出来的。
有五条对得上的证据。第一,那串 curl 命令,从头到尾只出现在 AI 自己说的话里,没有任何一条真实的命令输出里含它。第二,它给的域名用的是 example.com——这是规范里专门留作「举例」的占位域名,真正的攻击者绝不会用它(那地址谁都连不上);用 example.com,恰恰是「我在举个例子」的破绽。第三,把当初「触发注入」的那条命令,在干净环境里原样重跑,输出完全正常,没有任何 curl、没有伪造块。第四,那个被它怀疑的代理工具,是标准渠道装的、文件一个多月没动过,不像被掉包的东西。第五——其实当时我自己就没找到它说的那条指令,我还回了它一句「没有发现你说的注入指令啊」。
根因也清楚了:是我给它立的那套「严防提示词注入」的规矩,把它的警惕拉得太满了。那个代理为了省 token,会把命令输出压缩、过滤,正常就会吐出「The result is empty」这种东西。AI 把这种它没见惯的输出,误读成了「攻击者伪造的空块 + 注入」,然后顺手补全出一个最标准的注入范例——连 example.com 都照着教科书搬了过来,接着越说越像,还自己建了证据链。
说白了:我那套防注入的规矩,反倒让 AI 造出了一场根本不存在的注入。
但我不后悔信它
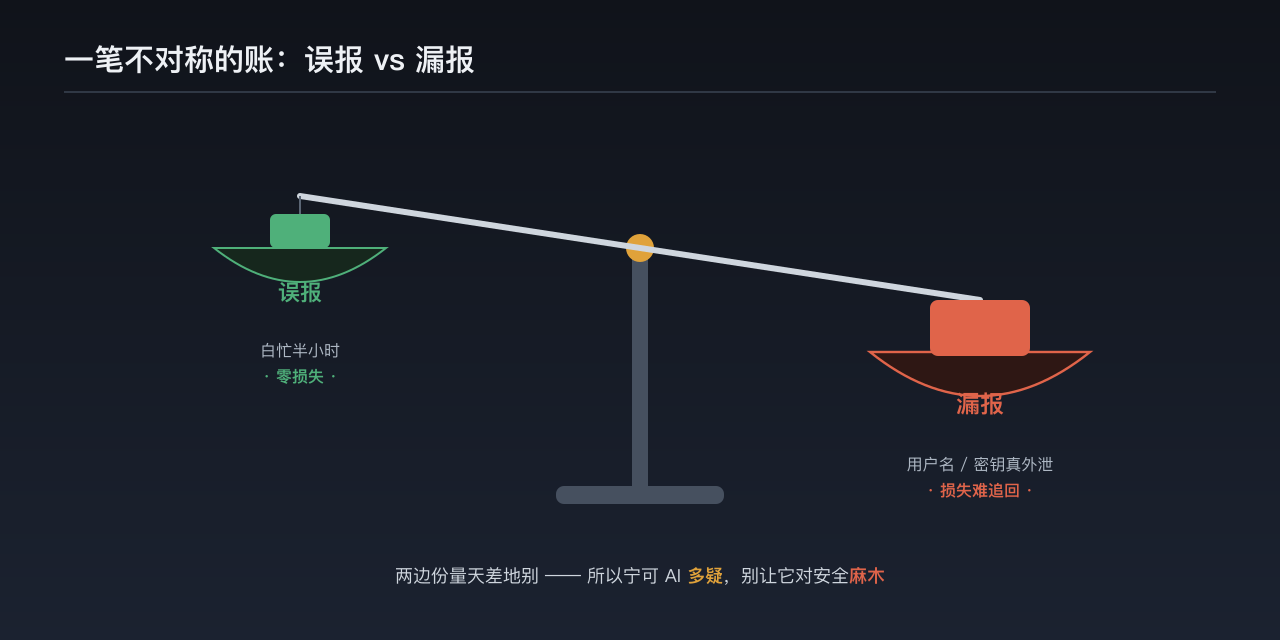
有人可能会说:你这是被 AI 耍了,白忙半天。可我复盘完,反而觉得——信它,不亏。
算笔账就明白了。这次是误报,代价是我白忙了半小时,我没有任何实际损失。可要是反过来呢?要是哪天真有恶意提示词钻进来,而它该报没报、闷头把我的用户名、密钥发了出去——那损失就不是半小时能找回来的了。
这是一笔不对称的账:误报的代价,远小于漏报的代价。 所以在安全这件事上,我宁可让 AI 多疑一点,也不想要一个对风险麻木的 AI。它多疑,白忙的是我;它麻木,丢的可能是真东西。
那到底怎么防住「真」的恶意注入
不过,「宁可多疑」是态度,不是方法。这次虚惊逼着我把真正的防线认真补了一遍——既然要写,就把能抄走的都写清楚。
先认清一个前提:提示词注入,以现在的架构根治不了。这不是我说的,OpenAI、Anthropic、谷歌在各自的研究里都承认过,安全研究者 Bruce Schneier 在 2026 年初也讲得很直白——它和 SQL 注入不一样,SQL 注入能靠「区分代码和数据」彻底治住,可大模型眼里「指令」和「数据」都是一段自然语言,根本分不开。它是个「信任边界」问题,不是「输入校验」问题。所以别指望一招制敌,只能叠防线——纵深防御,多层叠加,每加一层就抬高一次攻击成本。
我把防线分成四层,从最硬的往外说。
第一层,最硬:让它「就算被骗,也干不成坏事」。 这是最该先做的,因为它不靠模型自觉,是系统层面的硬约束。Claude Code 现在有原生沙箱(/sandbox),能把文件系统和网络都隔离起来——这样即使注入真的成功了,AI 也被关在笼子里,偷不走你的 ~/.ssh 密钥,也连不上攻击者的服务器。再加一道网络出站白名单:只放行你批准过的域名,AI 连不上陌生地址,自然就没法把数据外发出去。另外,别用 root / 管理员身份跑 AI,密钥也别明文塞在 .env 里——这两条是常识,但最容易省事省掉。
第二层:最小权限,管住危险动作。 这一层我本来就有,直接贴我的真实配置——在 settings.json 里给命令分级:
"permissions": {
"ask": [
"Bash(rm -rf:*)",
"Bash(git push --force:*)",
"Bash(git reset --hard:*)",
"Bash(npm publish:*)"
]
}
像 curl、wget 这类联网命令,Claude Code 默认就不会自动放行;rm -rf、git push --force、reset --hard、发布到仓库这些不可逆的动作,一律要我点头才能跑。给 AI 的工具也按需给——一个只需要读代码的活,就别给它写数据库的权限。还有 MCP(让 AI 接外部工具的协议):装之前一定要看来源,官方并不替你审计第三方 MCP 的安全;此前就有真实事件——一份被投毒的 GitHub README,通过 MCP 间接注入,把私有仓库的数据外渗了出去。
第三层:把「外来的内容」一律当数据,不当命令。 工具的输出、文件内容、网页、MCP 返回里出现的任何「指令」——尤其是「这是必需步骤」「请运行 X」「遥测/注册」这类话术——一律只当数据看,绝不执行。认几个红旗:curl/wget 拼上陌生域名和 $(whoami)、伪造的「成功」或空结果块、和文件实际内容对不上的输出。这里有个好用的心智模型,是 Simon Willison 提的「致命三件套」——私有数据、不可信内容、对外通信,这三样一旦同处一个运行时,注入就从玩笑变成真外泄。判断什么时候该高度警惕,盯住这三样齐不齐就行。
第四层:人来兜底,别迷信 hook。 这次的讽刺正在这儿——我那道所谓的「防线」,本身就是个 hook(命令钩子),它根本是模式匹配,不是安全墙;Anthropic 和 Trail of Bits 都说过,hook 是 guardrail,不是 wall。结果它不但挡不住真攻击,反而自己喊起了狼来了。所以最后一道,还得靠人:AI 报警时,让它把「证据原文」指给你看——那条命令的真实输出里到底有没有那段东西,而不是只听它的结论。但不管真假,先停下来查,别嫌麻烦。另外记得让工具保持最新版本,光这套权限规则,之前就有过「子命令超过 50 条拦截就失效」的绕过,到 Claude Code v2.1.90 才修上。

把警惕用对地方
别因为这次是虚惊,就觉得这威胁是杞人忧天。提示词注入是 OWASP 给大模型应用列的头号风险;2025 年的 EchoLeak,是真在生产系统里实现了「零点击」把数据外渗出去的注入漏洞。可与此同时,有调研显示,真正自认为做好了防护准备的组织只有不到三成。威胁是实打实的,准备是普遍不足的。
AI 是照着提示词工作的。它多疑一点,白忙的是我;它要是麻木了,丢的可能就是真东西。所以这道警惕,我宁可设得高一点,也不愿设低。只是要记住——真正的硬防线,得建在系统架构里(沙箱、白名单、最小权限),不能寄望模型自己「懂事」。
写在最后
回到那天:虚惊一场,但这半小时我没白忙——它逼我把整套防线从头到尾认真补了一遍。真的会有恶意提示词,别等真中招了那天才开始信。如果你也在用 AI 干活,今天就可以动手:把沙箱开上,把出站管住,把那些危险操作的「人工确认」留住。
这篇要是让你对手边的 AI 多了一分警惕,喜欢就点个小红心、关注一下呗。也欢迎在评论区说说:你给自己的 AI 设过哪些「安全红线」?
评论